
Skuteczna indeksacja zaczyna się dużo wcześniej niż sama pozycja w Google: od tego, czy robot wyszukiwarki w ogóle dotrze do strony, poprawnie ją odczyta i uzna za wartą zapisania w indeksie. W tym tekście rozkładam temat na praktyczne elementy: jak działa web crawler, co blokuje widoczność, jak odróżnić problemy z pobraniem strony od problemów z indeksacją i co realnie pomaga nowym treściom szybciej wejść do wyników.
Najważniejsze fakty o crawlerach i indeksacji
- Crawling to pobranie i odczytanie strony, a indeksacja to dopiero decyzja o zapisaniu jej w bazie wyszukiwarki.
- robots.txt nie służy do ukrywania treści przed Google, tylko do zarządzania dostępem i ruchem skanowania.
- Jeśli chcesz wykluczyć stronę z wyników, zwykle potrzebujesz noindex, a nie samego blokowania w robots.txt.
- sitemap pomaga Google szybciej odkryć ważne adresy, ale nie gwarantuje indeksacji.
- Na większych serwisach znaczenie ma crawl budget, czyli zasób czasu i uwagi, jaki robot poświęca witrynie.
- W praktyce największą różnicę robi dobra architektura linków, brak duplikatów i pełna dostępność treści dla robota.

Jak crawler odkrywa stronę i co robi potem
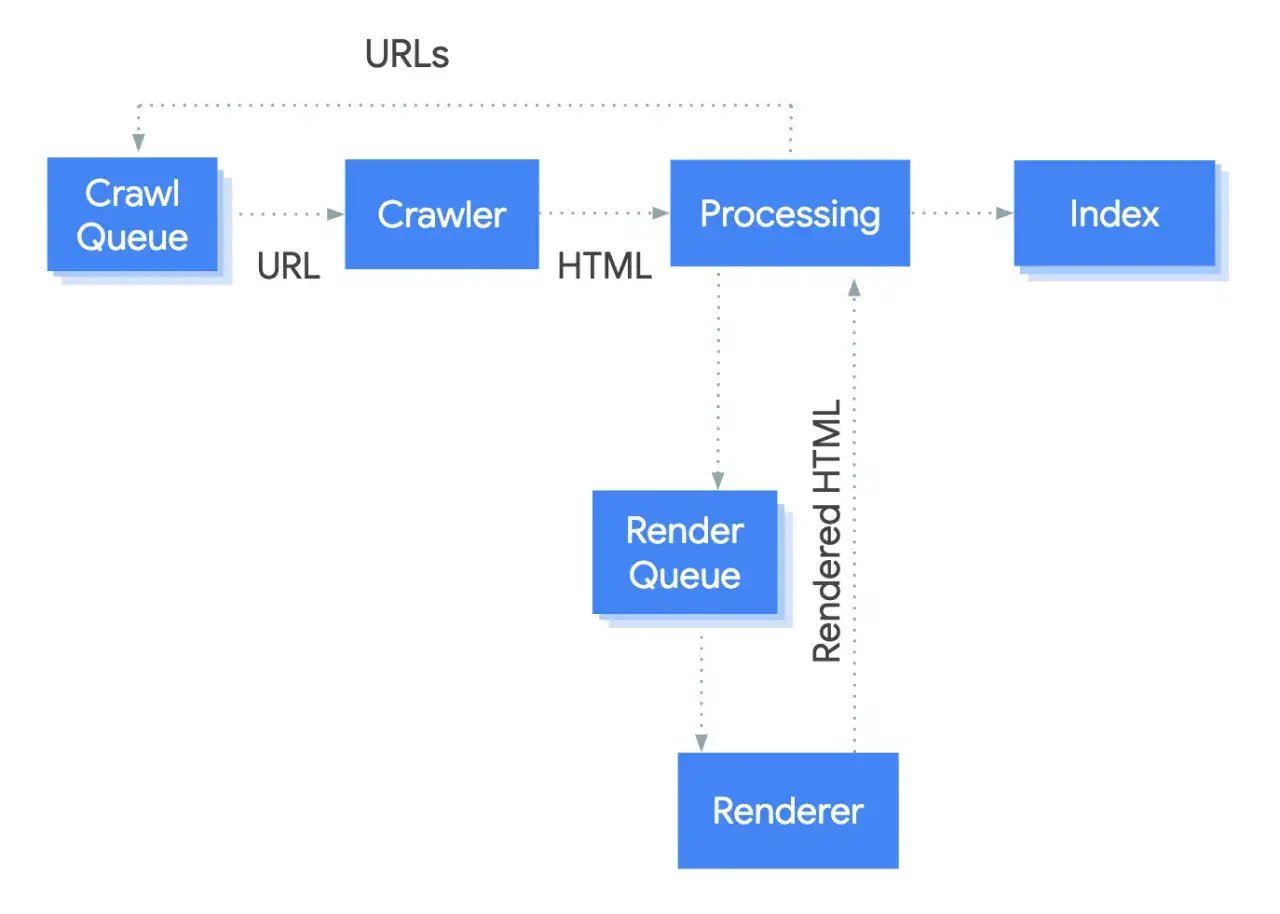
Najprościej ujmując, robot wyszukiwarki najpierw musi odnaleźć URL, potem pobrać jego zawartość, a następnie ocenić, czy strona nadaje się do zapisania w indeksie. Google Search Central przypomina, że nie ma centralnej listy wszystkich stron w sieci, więc wyszukiwarka stale szuka nowych i zaktualizowanych adresów. Źródłem odkrycia mogą być linki wewnętrzne, linki zewnętrzne, mapa witryny albo wcześniejsze znane adresy z tej samej domeny.W praktyce proces wygląda mniej więcej tak:
- robot trafia na adres przez link, sitemapę albo wcześniejszą znajomość serwisu,
- sprawdza, czy może pobrać treść i czy serwer odpowiada poprawnie,
- analizuje kod HTML, nagłówki, treść i sygnały techniczne,
- ocenia, czy strona nie jest duplikatem, cienką kopią innej podstrony albo zasobem zbyt słabym jakościowo,
- decyduje, czy zapisze ją w indeksie i jak będzie ją później interpretować.
Warto tu rozdzielić dwa etapy, które często wrzuca się do jednego worka. Crawling to pobranie strony, a indexing to zapisanie jej w bazie i przygotowanie do wyświetlania w wynikach. To rozróżnienie jest ważne, bo strona może zostać pobrana, a mimo to nie trafić do indeksu. I właśnie od tego zaczynają się najczęstsze problemy SEO.
Jeśli ten fundament jest jasny, łatwiej zrozumieć, dlaczego samo „Google już mnie odwiedziło” niczego jeszcze nie załatwia.
Dlaczego pobranie strony nie oznacza indeksacji
To jeden z najczęstszych błędów myślowych u właścicieli serwisów. Strona może być dostępna dla robota, ale mimo to nie zostać zapisana w indeksie, bo wyszukiwarka uzna ją za niewystarczająco wartościową, zbyt podobną do innych adresów albo technicznie niepewną. Google Search Central wprost rozdziela etap pobrania od decyzji o indeksacji.
Najczęstsze powody są zwykle dość prozaiczne:
| Sytuacja | Co to zwykle oznacza | Co sprawdzić |
|---|---|---|
| Strona została pobrana, ale nie ma jej w indeksie | Treść nie przekonała wyszukiwarki albo sygnały techniczne są zbyt słabe | unikalność treści, canonical, linkowanie wewnętrzne, jakość kodu |
| Adres jest znany, ale bez aktualizacji od dłuższego czasu | Robot nie widzi potrzeby częstszego odwiedzania | częstotliwość zmian, linki prowadzące do strony, mapa witryny |
| Google widzi wersję, ale wybiera inny adres kanoniczny | Uznał, że inny URL lepiej reprezentuje tę samą treść | canonical, przekierowania, duplikaty parametrów, wersje mobilne |
| Podstrona jest technicznie dostępna, lecz słaba jakościowo | Indeksacja nie jest opłacalna z perspektywy wyszukiwarki | wartość merytoryczna, kompletność, zgodność z intencją użytkownika |
Ja patrzę na to tak: indeksacja jest decyzją, nie automatem. Robot może wejść na stronę, ale to jeszcze nie znaczy, że wyszukiwarka uzna ją za najlepszą odpowiedź na czyjeś zapytanie. Dlatego w kolejnym kroku trzeba dobrze ustawić techniczne sygnały, a nie liczyć wyłącznie na „samo się zaindeksuje”.
robots.txt, noindex i canonical bez zamieszania
Tu najłatwiej o kosztowną pomyłkę. W praktyce te trzy mechanizmy pełnią różne role, a wielu osobom wydaje się, że działają zamiennie. Nie działają. robots.txt kontroluje dostęp robota do pobrania zasobu, noindex mówi wyszukiwarce, by nie trzymała strony w indeksie, a canonical wskazuje preferowaną wersję adresu, gdy kilka URL-i prowadzi do podobnej lub tej samej treści.
| Mechanizm | Do czego służy | Czego nie robi |
|---|---|---|
| robots.txt | Ogranicza pobieranie wybranych adresów i porządkuje ruch skanowania | Nie jest pewnym sposobem na ukrycie strony z wyników |
| noindex | Wskazuje, że strona nie ma trafiać do indeksu | Nie poprawia jakości treści i nie rozwiązuje duplikacji sam z siebie |
| canonical | Pomaga wskazać wersję główną przy podobnych adresach | Nie jest twardym poleceniem i nie zawsze zostanie bezwarunkowo przyjęty |
Jak przyspieszyć odkrywanie nowych treści
Jeśli publikujesz artykuł, produkt albo landing page i chcesz, żeby robot dotarł do niego możliwie szybko, nie liczyłbym na przypadek. Najlepiej działa zestaw prostych, konsekwentnych działań, które ułatwiają odkrycie i ocenę strony. Sama mapa witryny pomaga, ale nie daje gwarancji, bo jest tylko wskazówką, a nie obietnicą indeksacji.
- Dodaj sensowne linki wewnętrzne z już widocznych i mocnych podstron.
- Umieść adres w sitemapie, zwłaszcza jeśli to nowa lub głęboko ukryta podstrona.
- Unikaj osieroconych URL-i, czyli stron bez linków prowadzących z innych miejsc serwisu.
- Nie blokuj zasobów potrzebnych do renderowania, takich jak kluczowe pliki CSS i JavaScript.
- Upewnij się, że treść jest widoczna bez interakcji, bo elementy ładowane wyłącznie po kliknięciu bywają problematyczne.
- Sprawdzaj odpowiedzi serwera, bo częste błędy 5xx, wolne czasy odpowiedzi i przekierowania łańcuchowe spowalniają pracę robota.
W serwisach editorialowych i blogowych największą różnicę robi zwykle linkowanie z artykułów tematycznie bliskich, a nie sama publikacja w panelu CMS. W sklepach internetowych z kolei kluczowe stają się kategorie, filtrowanie i kontrola adresów parametrów, bo właśnie tam powstaje najwięcej niepotrzebnych URL-i. I tu dochodzimy do tematu, który zaczyna mieć znaczenie, gdy strona przestaje być mała.
Kiedy crawl budget naprawdę ma znaczenie
Crawl budget to po prostu zasób czasu i uwagi, jaki robot poświęca konkretnej witrynie. Google Search Central opisuje go jako połączenie dwóch elementów: możliwości technicznych i zapotrzebowania na ponowne odwiedziny. Na małej stronie ten temat bywa drugorzędny. Na dużym sklepie, portalu z tysiącami podstron albo serwisie z wieloma wariantami filtrowania to już jedna z głównych dźwigni SEO.
Najbardziej cierpią zwykle witryny, które generują ogromną liczbę słabych adresów:
- kombinacje filtrów prowadzące do niemal identycznych list produktów,
- strony z parametrami URL, które tworzą setki wariantów tej samej treści,
- duplikaty wersji mobilnej, językowej lub paginacji bez jasnej hierarchii,
- stare, nieaktualne podstrony, które nadal wiszą w strukturze i rozpraszają skanowanie.
W takich projektach optymalizacja nie polega na „proszeniu Google o częstsze wejścia”, tylko na porządkowaniu przestrzeni, po której robot ma się poruszać. Usuwam śmieciowe adresy, skracam ścieżki do ważnych podstron, porządkuję canonicale i dbam o to, by ważne treści były dostępne z kilku logicznych miejsc. To zwykle działa lepiej niż jakiekolwiek sztuczne przyspieszacze.
Jeżeli serwis jest niewielki, crawl budget nie powinien być pierwszą obsesją. Jeśli jednak masz rozbudowaną architekturę lub tysiące adresów, ten temat bardzo szybko przestaje być teoretyczny.
Najczęstsze błędy, które widzę w Search Console
W praktyce problemy z indeksacją najłatwiej diagnozować po komunikatach i raportach w Search Console. Nie trzeba znać każdego technicznego niuansu, żeby zauważyć wzorzec. Jeśli kilka kluczowych podstron ciągle wypada z indeksu, zwykle winny jest jeden z kilku klasycznych scenariuszy.- Strona jest zablokowana przez robots.txt mimo że właściciel chciał tylko wyłączyć ją z wyników.
- noindex został dodany przypadkowo po migracji, wdrożeniu CMS-a albo zmianie szablonu.
- canonical wskazuje na zły adres, przez co Google wybiera inną wersję niż ta, na której zależy serwisowi.
- Treść ładuje się dopiero po akcji użytkownika, więc robot widzi zubożoną wersję strony.
- Duplikaty są zbyt podobne i wyszukiwarka wybiera tylko jedną wersję, resztę pomijając.
- Adres jest dostępny, ale słabo podlinkowany, więc robot trafia na niego zbyt rzadko.
Warto też zwracać uwagę na statusy typu „discovered, currently not indexed” albo „crawled, currently not indexed”. Pierwszy zwykle sugeruje, że Google zna adres, ale jeszcze do niego nie doszedł lub nie uznał za priorytetowy. Drugi oznacza, że strona została pobrana, ale nie przeszła selekcji do indeksu. To dwa różne sygnały i wymagają trochę innej reakcji. Gdy rozpoznasz te różnice, łatwiej przejdziesz do prostego, praktycznego audytu przed publikacją.
Co sprawdzam przed publikacją ważnej podstrony
Jeżeli mam wypuścić stronę, na której naprawdę mi zależy, zawsze robię krótki przegląd techniczny. To nie jest skomplikowane, ale oszczędza dużo czasu, bo pozwala wyłapać rzeczy, które później blokują indeksację albo osłabiają sygnały jakości. Najczęściej sprawdzam te elementy:
- czy adres jest osiągalny bez błędów serwera i bez zbędnych przekierowań,
- czy strona nie ma przypadkiem noindex ani blokady w robots.txt,
- czy canonical wskazuje właściwą wersję URL,
- czy najważniejsza treść jest widoczna w HTML od razu, bez czekania na interakcję,
- czy podstrona jest podlinkowana z kilku sensownych miejsc w serwisie,
- czy sitemap została zaktualizowana i obejmuje nowy adres,
- czy tytuł, nagłówki i treść rzeczywiście odpowiadają jednej, konkretnej intencji użytkownika.
Ta checklista brzmi prosto, ale właśnie w prostych miejscach najczęściej kryją się straty. Dobrze ustawiony serwis nie musi „walczyć” z robotem, tylko pomaga mu zrozumieć, które strony są ważne, które są duplikatami, a które nie powinny trafiać do indeksu. Jeśli ten porządek jest zrobiony, cały proces widoczności w Google staje się dużo stabilniejszy i mniej losowy.