Indeksacja to ten etap SEO, który decyduje, czy cała dalsza praca ma w ogóle sens. Nawet dobrze napisana strona, szybki serwis i sensowna architektura nie dadzą efektu, jeśli Google nie zobaczy treści albo uzna, że nie warto jej dodawać do indeksu. Właśnie dlatego dobry specjalista SEO nie zaczyna od „upchania słowa kluczowego”, tylko od sprawdzenia, czy strona jest dostępna, zrozumiała i technicznie gotowa do wejścia do wyników.
Najważniejsze rzeczy o indeksacji, zanim zaczniesz poprawiać widoczność
- Google musi najpierw znaleźć stronę, potem ją odczytać, a dopiero później dodać do indeksu.
- Blokady w robots.txt, tag noindex, błędy 4xx i 5xx oraz błędny canonical potrafią zatrzymać stronę zanim pojawi się w wynikach.
- Nowa podstrona nie trafia do indeksu natychmiast; recrawl zwykle trwa od kilku dni do kilku tygodni.
- Search Console pokazuje, czy problem leży po stronie crawl, indeksowania czy jakości treści.
- Najlepiej działają: dobra architektura, sensowne linkowanie wewnętrzne, sitemap i treści, które naprawdę coś wnoszą.
Co robi specjalista SEO, gdy problemem jest indeksacja
W praktyce nie patrzę na indeksację jak na jedną usterkę, tylko jak na cały łańcuch zależności. Najpierw trzeba ustalić, czy Google w ogóle dociera do adresu URL, potem czy może go poprawnie odczytać, a dopiero na końcu, czy uznaje stronę za wartą dodania do indeksu. To różnica, która w wielu projektach oszczędza dni błądzenia po omacku.
Praca przy indeksacji zwykle oznacza trzy równoległe obszary: technikę, strukturę serwisu i jakość samej treści. Na poziomie technicznym sprawdzam odpowiedzi serwera, dyrektywy dla robotów, canonicale i rendering. Na poziomie struktury patrzę, czy ważne strony nie są „sierotami”, czyli nie wiszą bez sensownych linków wewnętrznych. Na poziomie treści oceniam, czy podstrona wnosi coś unikalnego, czy tylko powiela inne materiały.
- Rozdzielam problem crawlability od problemu indexability, bo to nie to samo.
- Sprawdzam, czy Google widzi właściwą wersję strony, a nie wariant testowy, filtr albo kopię.
- Patrzę, czy treść odpowiada na realną potrzebę, czy jest zbyt cienka, zbyt podobna lub zbyt chaotyczna.
Jeśli ten porządek jest jasny, łatwiej zrozumieć sam mechanizm działania Google, a to prowadzi wprost do następnej części.
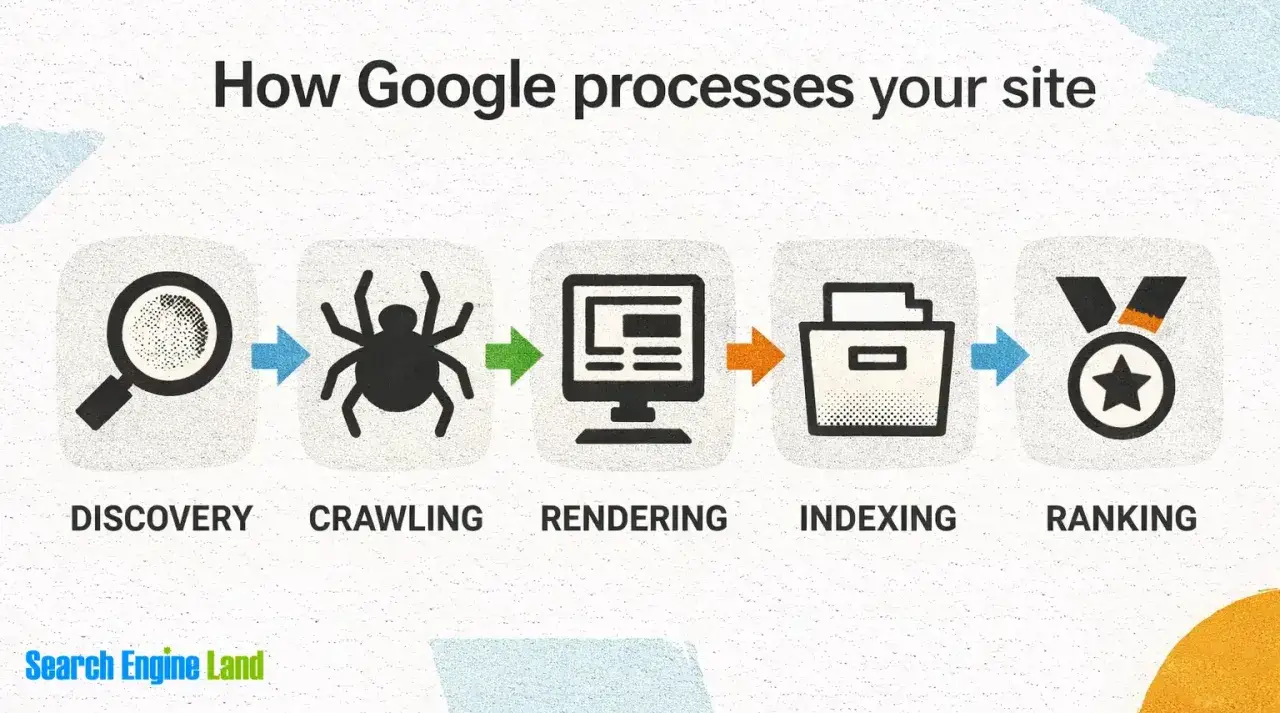
Jak Google przechodzi od znalezienia strony do jej indeksu
W uproszczeniu są tu cztery kroki: discovery, crawl, render i index. Google najpierw odkrywa adres, potem go odwiedza, później przetwarza treść strony, w tym ewentualny JavaScript, a na końcu decyduje, czy materiał trafi do indeksu. Sam fakt, że strona istnieje, nie oznacza jeszcze, że zostanie zaakceptowana do wyników.
Google Search Central podkreśla kilka warunków, które muszą być spełnione: strona ma być publicznie dostępna, nie może blokować Googlebota, musi zwracać poprawny status HTTP 200 i zawierać treść, którą da się zindeksować. Jeśli strona jest prywatna, wymaga logowania albo zwraca błąd, proces zatrzymuje się wcześniej.Ważne jest też rozróżnienie między robots.txt a noindex. Pierwsze blokuje crawl, drugie blokuje indeksację, ale pozwala Google zobaczyć URL. To nie jest detal techniczny dla pedantów, tylko częsty powód, dla którego strona niby „żyje”, a nie pojawia się w wynikach.
Na stronach opartych o mocny JavaScript, headless CMS albo frameworki typu Next.js problemem bywa renderowanie. Google może znaleźć URL, ale jeśli finalna treść pojawia się dopiero po stronie klienta w sposób trudny do przetworzenia, indeksacja robi się mniej przewidywalna. To właśnie dlatego w projektach technologicznych nie wystarcza ładny frontend. Trzeba jeszcze zadbać, żeby crawler zobaczył to, co ma zobaczyć.
Kiedy mechanizm jest zrozumiany, łatwiej przejść do rzeczy najbardziej praktycznej, czyli do miejsc, w których indeksacja najczęściej się wykłada.
Najczęstsze blokady, przez które strona nie trafia do indeksu
W audytach najczęściej widzę nie jeden błąd, tylko ich zestaw. Jedna podstrona ma canonical wskazujący na inną wersję, druga dostaje tag noindex po wdrożeniu, trzecia zwraca 200, ale zawiera tak mało treści, że Google uznaje ją za mało wartościową. Efekt końcowy wygląda podobnie: URL istnieje, ale nie daje ruchu.
| Objaw | Co zwykle oznacza | Co sprawdzić najpierw |
|---|---|---|
| Strona jest znana, ale nie pojawia się w wynikach | Może być wykluczona przez noindex, canonical albo zbyt słabą jakość treści | Źródło strony, nagłówki HTTP, canonical i raport indeksowania |
| Google nie może wejść na URL | Blokuje go robots.txt, reguła serwera albo problem z dostępnością | Test w Search Console, status HTTP, logika reguł robots |
| Adres zwraca błąd albo zachowuje się niestabilnie | 4xx, 5xx, soft 404 lub problem z przekierowaniem | HTTP status, łańcuch przekierowań, zachowanie strony po wejściu |
| Zaindeksowała się nie ta wersja strony | Google wybrał inny canonical niż ten, którego oczekujesz | Rel canonical, linki wewnętrzne, sitemap i duplikaty URL |
| Nowy artykuł długo nie trafia do indeksu | Strona jest zbyt odosobniona albo ma zbyt mało sygnałów jakości | Linkowanie wewnętrzne, sitemap, unikalność i dopasowanie do intencji |
| Widoczność spada po przebudowie serwisu | Migracja, zmiana struktury lub problem z renderowaniem | Przekierowania, mapowanie URL-i, testy na środowisku stagingowym |
Najbardziej mylący jest stan, w którym wszystko wygląda poprawnie „na pierwszy rzut oka”, ale Google i tak nie indeksuje podstrony. Wtedy trzeba wejść głębiej, najlepiej przez Search Console i sam kod strony.
Jak diagnozuję indeksację w Search Console i na stronie
Zaczynam od URL Inspection, bo to najszybszy sposób, żeby zobaczyć, co Google faktycznie myśli o konkretnej podstronie. Interesuje mnie przede wszystkim, czy strona jest dostępna dla bota, jaki kod HTTP zwraca, jaki canonical został wskazany i czy nie ma jawnej blokady indeksowania. Sama obecność w panelu nie wystarcza; liczy się interpretacja danych.
- Sprawdzam, czy Google może crawlować stronę.
- Patrzę, czy indeksowanie nie jest jawnie wyłączone przez noindex lub nagłówki serwera.
- Porównuję canonical z rzeczywistą wersją strony, która ma rankować.
- Weryfikuję, czy URL jest w sitemapie i czy jest linkowany z ważnych, już zindeksowanych sekcji serwisu.
- Oglądam, czy treść po renderze nadal jest pełna i czy nie znika ważny fragment przez JavaScript.
W praktyce bardzo pomagają też dwa raporty: Page Indexing i Crawl Stats. Pierwszy pokazuje, które adresy są wykluczane i dlaczego, drugi zdradza, jak często Googlebot odwiedza serwis i czy nie ma problemów z dostępnością. To zestaw, który pozwala odróżnić przypadkowy incydent od problemu systemowego.
Jeśli strona została dopiero opublikowana, można poprosić o ponowne przeskanowanie, ale warto mieć realistyczne oczekiwania. Jak podaje Google Search Central, crawl może zająć od kilku dni do kilku tygodni, a samo zgłoszenie nie gwarantuje natychmiastowego wejścia do indeksu. To kolejny powód, dla którego lepiej usuwać blokady, niż liczyć na cudowny przycisk „indeksuj”.
Gdy diagnostyka jest poukładana, można przejść do tego, co faktycznie przyspiesza wejście nowych treści do indeksu.
Co realnie przyspiesza wejście nowych treści do indeksu
Najlepsze efekty daje nie spryt, tylko przewidywalność. W większości projektów szybciej indeksują się te strony, które są dobrze osadzone w strukturze serwisu, mają czysty kod, sensowny canonical i nie próbują udawać, że trzy akapity powielone z innej podstrony są pełnowartościowym materiałem.
- Linkowanie wewnętrzne z już zindeksowanych stron pomaga Google odkryć nowy URL bez zgadywania.
- Sitemap daje sygnał, że strona jest świeża lub zaktualizowana, ale nie wymusza indeksacji.
- Jedna właściwa wersja URL ogranicza duplikację i rozmywanie sygnałów.
- Poprawny status 200 i brak blokad technicznych zdejmują najprostsze przeszkody.
- Treść odpowiadająca na konkretną intencję zwiększa szansę, że Google uzna stronę za warta dodania do indeksu.
Na większych serwisach dochodzi jeszcze kwestia crawl budget, czyli tego, ile uwagi robot poświęca domenie. Jeśli portal generuje dużo podobnych adresów, filtrów, tagów albo paginacji, Google może marnować zasoby na strony drugorzędne zamiast na te naprawdę ważne. Wtedy pomagają porządek w architekturze, ograniczenie duplikatów i lepsza hierarchia linków.
W projektach technicznych, zwłaszcza opartych o nowoczesne frameworki, widzę też jedną powtarzalną zależność: im bardziej złożony frontend, tym większa potrzeba współpracy między SEO a developerami. Sam opis treści nie wystarczy, jeśli render, routing lub przekierowania są źle ustawione.
To prowadzi do praktycznego pytania: kiedy taki problem da się ogarnąć samodzielnie, a kiedy naprawdę potrzebne jest wsparcie z zewnątrz?
Kiedy warto oddać temat specjaliście, a kiedy wystarczy własna checklista
Jeśli prowadzisz niewielki serwis, publikujesz kilka lub kilkanaście treści miesięcznie i korzystasz ze standardowego CMS-a, często wystarczy dobra checklista. W takim układzie większość problemów dotyczy prostych błędów: przypadkowego noindex, źle ustawionej strony kanonicznej, słabego linkowania albo braku wpisu w sitemapie.
Inaczej wygląda to przy dużym portalu, sklepie, serwisie z filtrowaniem albo stronach budowanych dynamicznie. Tam jedna zła decyzja dotycząca indexacji potrafi zablokować setki adresów. W takich projektach potrzebny jest ktoś, kto potrafi połączyć SEO, treść i zachowanie aplikacji webowej, a nie tylko sprawdzić meta tagi.
| Sytuacja | Wystarczy własna checklista | Lepiej włączyć specjalistę |
|---|---|---|
| Mały blog lub prosty serwis firmowy | Tak, jeśli problem jest pojedynczy i technicznie prosty | Nie zawsze potrzebne |
| Nowy portal z wieloma kategoriami i tagami | Raczej nie | Tak, bo łatwo o duplikację i chaos w crawl |
| Migracja domeny lub przebudowa URL-i | Tylko przy małej skali | Tak, bo ryzyko utraty indeksu jest wysokie |
| Serwis oparty o JavaScript, headless CMS lub własny framework | Rzadko | Tak, bo problemem bywa renderowanie i routing |
| Spadek liczby zaindeksowanych stron bez oczywistej przyczyny | Niepewne | Tak, bo trzeba szukać przyczyny systemowej |
W praktyce dobry specjalista SEO jest najbardziej potrzebny wtedy, gdy problem nie leży w jednym tagu, tylko w całym sposobie budowy serwisu. To właśnie tam indeksacja przestaje być prostym zadaniem technicznym, a staje się częścią architektury produktu.
Co sprawdzić przed publikacją, żeby nowa strona nie utknęła poza indeksem
Najbardziej opłaca mi się myśleć o indeksacji jeszcze przed kliknięciem „opublikuj”. Jeśli URL ma zwracać 200, nie może mieć noindex, powinien wskazywać właściwy canonical i być podlinkowany z sensownego miejsca w serwisie, to szansa na sprawne wejście do indeksu rośnie bardzo mocno. W praktyce to oszczędza późniejszych poprawek, które zwykle są droższe niż porządne wdrożenie na starcie.
- Sprawdź, czy strona nie jest zablokowana w robots.txt.
- Upewnij się, że nie ma tagu noindex ani blokującego nagłówka.
- Zweryfikuj canonical i przekierowania.
- Dodaj URL do sitemap i linkuj go z już mocnych, zindeksowanych sekcji.
- Zadbaj o treść, która nie powiela innych podstron i odpowiada na konkretną potrzebę.
- Po publikacji zgłoś recrawl tylko wtedy, gdy ma to sens, a potem daj Google czas na pracę.
Jeśli ten zestaw jest dopięty, indeksacja przestaje być loterią, a staje się przewidywalnym etapem pracy nad serwisem. I właśnie na tym polega dobra techniczna SEO: nie na sztuczkach, tylko na usuwaniu przeszkód, zanim jeszcze zdążą kosztować widoczność.