
W dzisiejszym, niezwykle konkurencyjnym świecie cyfrowym, gdzie algorytmy wyszukiwarek ewoluują w zawrotnym tempie, a treści generowane przez sztuczną inteligencję zalewają sieć, zrozumienie i optymalizacja budżetu indeksowania (crawl budget) stały się absolutnie kluczowe dla utrzymania i poprawy widoczności strony w wynikach wyszukiwania. Ten artykuł dostarczy Ci kompleksowej wiedzy, od podstaw teoretycznych po praktyczne strategie, które pomogą Ci efektywnie zarządzać zasobami Googlebota, co jest nieocenione zwłaszcza dla właścicieli dużych portali i sklepów internetowych.
Crawl Budget: Dlaczego w dobie AI i ogromnej konkurencji to pojęcie stało się kluczowe dla Twojego SEO?
Obecne środowisko internetowe jest dynamiczne jak nigdy dotąd. Ogromna ilość nowej treści pojawiającej się każdego dnia, często generowanej przez zaawansowane algorytmy AI, w połączeniu z rosnącą konkurencją, stawia przed właścicielami stron internetowych coraz większe wyzwania. W tym kontekście, optymalizacja budżetu indeksowania (crawl budget) przestaje być jedynie technicznym aspektem SEO, a staje się fundamentalnym elementem strategii. Musimy pamiętać, że Google dysponuje ograniczonymi zasobami, a sposób, w jaki te zasoby są wykorzystywane do skanowania naszej witryny, bezpośrednio wpływa na to, czy nasze treści zostaną w ogóle zauważone przez wyszukiwarkę i tym samym czy będą miały szansę pojawić się w wynikach wyszukiwania.
Wstęp: Nie każda Twoja podstrona zostanie zauważona przez Google
Wyobraźmy sobie, że Googlebot to zapracowany kurier, który musi dostarczyć paczki (zindeksować strony) do milionów adresatów na całym świecie. Nie jest w stanie odwiedzić każdego domu każdego dnia, ani nawet każdej podstrony na każdej posesji. Szczególnie w przypadku dużych serwisów takich jak rozbudowane sklepy internetowe z tysiącami produktów czy portale informacyjne z ciągle aktualizowanymi artykułami liczba adresów URL idzie w setki tysięcy, a nawet miliony. W takim gąszczu, Googlebot musi priorytetyzować, które strony odwiedzić i kiedy. Jeśli Twoje kluczowe podstrony nie znajdą się na tej liście, nie zostaną zaindeksowane, a brak indeksacji to brak jakiejkolwiek szansy na ranking i widoczność.
Kiedy optymalizacja budżetu indeksowania jest absolutnie konieczna? (Checklista)
Istnieją pewne sytuacje i typy witryn, w których zaniedbanie optymalizacji budżetu indeksowania może prowadzić do poważnych problemów z widocznością. Jeśli Twoja strona wpisuje się w którykolwiek z poniższych punktów, powinieneś potraktować crawl budget jako priorytet:
- Duże sklepy internetowe: Zazwyczaj posiadają ogromną liczbę produktów, kategorii i podstron, często generowanych dynamicznie.
- Portale informacyjne i serwisy newsowe: Wymagają szybkiego indeksowania nowych treści, aby być konkurencyjnymi.
- Witryny z dynamicznie generowanymi treściami: Takie jak fora dyskusyjne, strony z wynikami wyszukiwania wewnętrznego, czy profile użytkowników.
- Strony z historią problemów technicznych: Długi czas odpowiedzi serwera, częste błędy 4xx lub 5xx mogą negatywnie wpływać na przydzielany budżet.
- Serwisy z dużą ilością treści o niskiej wartości lub duplikatów: Automatycznie generowane strony, strony z minimalną ilością tekstu, czy strony z powtarzającą się zawartością.
- Witryny, które przeszły znaczące zmiany: Nowa struktura, migracja na inny serwer lub domena mogą wymagać ponownego "przekonania" Googlebota do efektywnego indeksowania.
Crawl Budget bez tajemnic: Czym jest i jak Google decyduje, ile uwagi poświęcić Twojej stronie?
Zrozumienie, czym dokładnie jest budżet indeksowania i jakie mechanizmy nim rządzą, jest kluczowe do jego skutecznej optymalizacji. Wbrew pozorom, nie jest to coś, co Google nam oficjalnie przyznaje, ale raczej zasób, który musimy sobie "wypracować" poprzez dobrą kondycję techniczną i jakość naszej witryny.
Definicja dla każdego: Crawl budget jako "czas antenowy" w Google
Najprościej rzecz ujmując, crawl budget to nic innego jak czas i zasoby, które Googlebot poświęca na skanowanie Twojej witryny. Możemy to porównać do "czasu antenowego" im więcej uwagi Google poświęci Twojej stronie, tym większa szansa, że zostanie ona dokładnie przeanalizowana i zaindeksowana. Ważne jest, aby podkreślić, że crawl budget nie jest bezpośrednim czynnikiem rankingowym, czyli nie znajdziemy go na liście elementów decydujących o pozycji strony w wynikach wyszukiwania. Jednak jego efektywne wykorzystanie jest warunkiem koniecznym do szybkiego i kompletnego zaindeksowania treści, co z kolei jest fundamentem jakiejkolwiek widoczności.
Kluczowe składniki: Crawl Rate Limit vs. Crawl Demand – co musisz o nich wiedzieć?
Google definiuje budżet indeksowania jako kombinację dwóch głównych elementów, które wspólnie determinują, ile razy i jak szybko Googlebot odwiedzi Twoją stronę:
- Crawl Rate Limit (Limit Szybkości Indeksowania): To techniczne ograniczenie, które określa maksymalną liczbę jednoczesnych połączeń, jakie Googlebot może nawiązać z Twoim serwerem. Jest to mechanizm ochronny, mający zapobiec przeciążeniu witryny. Na ten limit wpływa przede wszystkim wydajność Twojego serwera. Jeśli strona ładuje się wolno, często zwraca błędy serwera (np. 5xx) lub ma problemy z dostępnością, Googlebot automatycznie obniży swój limit, odwiedzając Twoją witrynę rzadziej i z mniejszą intensywnością.
- Crawl Demand (Zapotrzebowanie na Indeksowanie): Ten element odnosi się do tego, jak "pilne" jest dla Google zaindeksowanie Twojej strony. Zapotrzebowanie na indeksowanie jest wyższe dla stron, które są często aktualizowane, posiadają wysokiej jakości, unikalne treści i są popularne (mają wiele linków przychodzących). Strony, które rzadko się zmieniają, są mało popularne lub zawierają treści o niskiej wartości, będą odwiedzane przez Googlebota znacznie rzadziej, ponieważ wyszukiwarka uznaje je za mniej priorytetowe.
Dlaczego crawl budget nie jest czynnikiem rankingowym, a i tak decyduje o Twojej widoczności?
Może się wydawać to paradoksalne: jak coś, co nie jest czynnikiem rankingowym, może decydować o widoczności? Odpowiedź jest prosta: jeśli Twoja strona nie zostanie zaindeksowana, nie ma szansy pojawić się w wynikach wyszukiwania, niezależnie od tego, jak doskonała jest jej treść czy jak silne ma linkowanie. Crawl budget jest więc warunkiem wstępnym. Zapewnia, że Googlebot ma możliwość "zobaczenia" i "zrozumienia" Twojej strony. Bez tego fundamentu, wszystkie inne działania optymalizacyjne stają się bezcelowe, ponieważ wyszukiwarka po prostu nie będzie miała co oceniać.
Audyt własnej strony: Jak sprawdzić, czy nie marnujesz budżetu na indeksowanie?
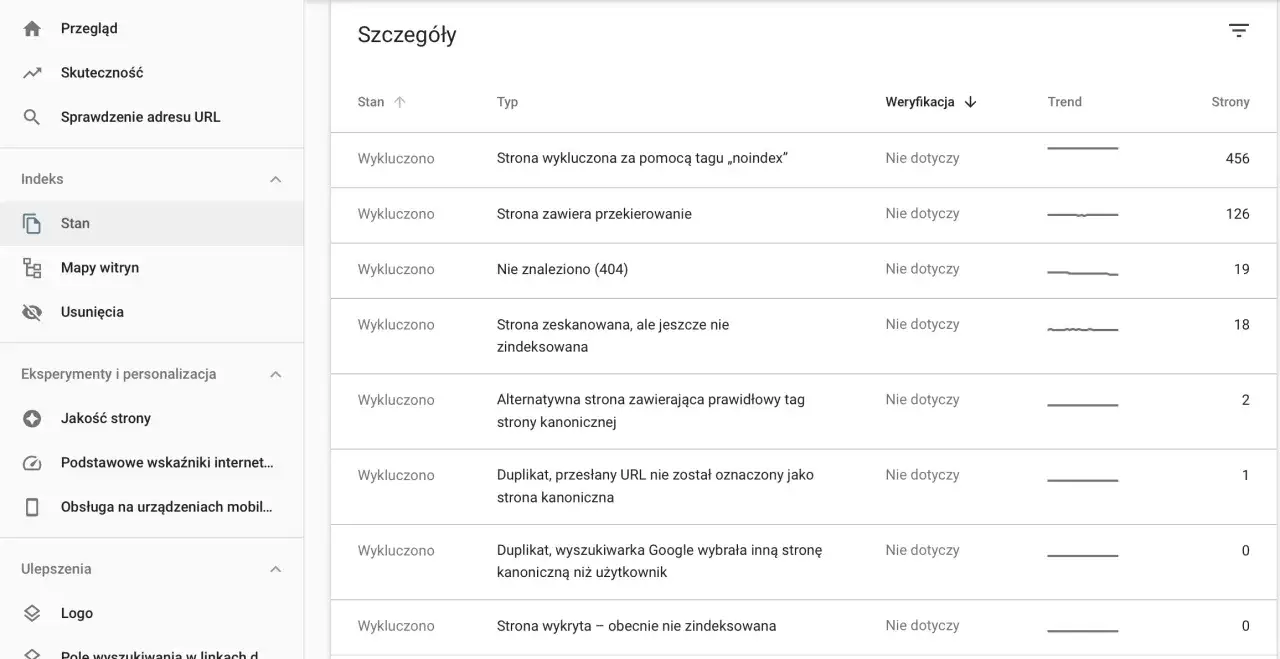
Zanim zaczniemy wdrażać jakiekolwiek zmiany, musimy dokładnie zdiagnozować obecny stan naszej witryny. Na szczęście, Google dostarcza nam potężne narzędzie, które jest do tego celu idealne Google Search Console. Pozwala ono nie tylko monitorować aktywność Googlebota, ale także identyfikować potencjalne problemy.Google Search Console jako Twoje centrum dowodzenia: Analiza raportu "Statystyki indeksowania"
Najważniejszym miejscem do rozpoczęcia audytu jest raport "Statystyki indeksowania", który znajdziesz w menu Google Search Console, zazwyczaj w zakładce "Indeksowanie". Ten raport dostarcza cennych informacji na temat tego, jak Googlebot odwiedza Twoją stronę. Zwróć uwagę na następujące dane:
- Liczba żądań indeksowania: Pokazuje, jak często Googlebot odwiedza Twoją witrynę.
- Pobrane dane: Informuje o rozmiarze danych pobranych przez Googlebota.
- Czas odpowiedzi serwera: Kluczowy wskaźnik pokazujący, jak szybko serwer odpowiada na żądania.
Analiza tych danych pozwala nam zrozumieć ogólną aktywność Googlebota na naszej stronie i wychwycić niepokojące trendy.
Na co zwrócić uwagę na wykresach? Interpretacja liczby żądań, rozmiaru pobierania i czasu odpowiedzi
Przyjrzyjmy się bliżej kluczowym wskaźnikom:
- Liczba żądań indeksowania: Nagłe, drastyczne spadki w tym wykresie mogą oznaczać, że Googlebot napotyka problemy z dostępem do strony lub jej wydajnością, co prowadzi do zmniejszenia częstotliwości odwiedzin. Z kolei nieuzasadnione, gwałtowne wzrosty mogą sugerować, że bot indeksuje dużą liczbę niepotrzebnych lub niskowartościowych stron.
- Pobrane dane: Jeśli rozmiar pobranych danych jest bardzo mały w stosunku do liczby żądań, może to oznaczać, że Googlebot odwiedza strony z minimalną ilością treści (thin content). Jeśli jest bardzo duży, a liczba żądań jest niska, może to wskazywać na problemy z wydajnością serwera.
- Czas odpowiedzi serwera: Długi czas odpowiedzi serwera jest sygnałem alarmowym. Im dłużej serwer odpowiada, tym bardziej obciąża to Googlebota i tym niższy będzie jego Crawl Rate Limit. Idealnie, czas odpowiedzi powinien być jak najkrótszy.
Sygnały alarmowe: Kiedy powolne indeksowanie nowych treści to wina crawl budget?
Istnieje kilka symptomów, które mogą wskazywać na problemy z budżetem indeksowania:- Opóźnione pojawianie się nowych artykułów w wynikach wyszukiwania: Jeśli po publikacji artykułu mija wiele dni lub tygodni, zanim pojawi się on w Google, może to oznaczać, że Googlebot nie odwiedza Twojej strony na tyle często, by go szybko odkryć i zaindeksować.
- Wolne aktualizowanie zmian na stronie: Podobnie, jeśli zmiany wprowadzone na istniejących podstronach są widoczne w Google dopiero po długim czasie, może to być wina niskiego Crawl Demand lub Limit Szybkości.
- Brak indeksacji ważnych podstron: Jeśli kluczowe strony Twojej witryny (np. strony produktowe, kategorie) nie są indeksowane, mimo że są poprawnie zlinkowane, problemem może być właśnie ograniczony budżet.
Zaawansowana diagnostyka: Kiedy warto sięgnąć po analizę logów serwera?
Google Search Console dostarcza nam cennych wskazówek, ale dla pełnej, dogłębnej analizy, zwłaszcza w przypadku bardzo dużych serwisów, niezbędna może okazać się analiza logów serwera. Logi serwera to szczegółowe zapisy wszystkich żądań kierowanych do Twojego serwera, w tym tych pochodzących od robotów wyszukiwarek. Pozwalają one na precyzyjne zidentyfikowanie, które adresy URL są odwiedzane przez Googlebota, jak często, jakie błędy napotyka, a także jakie typy botów (np. Googlebot-Image, Googlebot-News) odwiedzają Twoją stronę. Jest to metoda wymagająca większej wiedzy technicznej, ale daje nieoceniony wgląd w rzeczywiste zachowanie robotów.
Główni winowajcy: Co najczęściej pożera Twój budżet indeksowania?
Istnieje szereg powszechnych problemów technicznych i strategicznych, które mogą prowadzić do nieefektywnego wykorzystania budżetu indeksowania. Ich identyfikacja i eliminacja to podstawa optymalizacji.
Pułapki nawigacji fasetowej: Jak filtry i sortowanie w e-commerce generują tysiące bezwartościowych URL-i?
W sklepach internetowych nawigacja fasetowa czyli mechanizmy filtrowania i sortowania produktów (np. po cenie, kolorze, rozmiarze) jest niezwykle ważna dla użytkowników. Niestety, może być również jednym z największych pożeraczy budżetu indeksowania. Każda kombinacja filtrów i opcji sortowania może generować unikalny adres URL. Jeśli te adresy nie są odpowiednio zarządzane (np. poprzez tagi kanoniczne lub blokowanie w robots.txt), Googlebot może próbować indeksować tysiące, a nawet miliony identycznych lub bardzo podobnych stron, co jest ogromnym marnotrawstwem zasobów.
Techniczny bałagan: Błędy 404, pętle przekierowań i błędy serwera (5xx)
Problemy techniczne są bezpośrednim zagrożeniem dla budżetu indeksowania:- Błędy 404 (nie znaleziono): Kiedy Googlebot próbuje odwiedzić adres URL, który już nie istnieje, jest to dla niego sygnał do zaprzestania dalszych prób na tej ścieżce. Każde takie żądanie to jednak zmarnowany zasób.
- Łańcuchy przekierowań (301): Przekierowania są potrzebne, ale ich nadmierna liczba lub tworzenie długich łańcuchów (np. strona A przekierowuje do B, B do C, C do D) sprawia, że Googlebot musi wykonać wiele dodatkowych kroków, zanim dotrze do docelowej strony. Każde takie przekierowanie to dodatkowe żądanie i obciążenie dla budżetu.
- Błędy serwera (5xx): Te błędy sygnalizują poważne problemy z dostępnością lub wydajnością serwera. Googlebot, napotykając je, zrozumie, że strona jest niestabilna i zacznie ograniczać swoje odwiedziny, co bezpośrednio wpływa na Crawl Rate Limit.
Problem zduplikowanej treści: Jak identyczne strony zjadają cenne zasoby robota?
Duplikacja treści to sytuacja, w której na Twojej stronie znajduje się wiele adresów URL prowadzących do tej samej lub bardzo podobnej zawartości. Może to wynikać z różnych przyczyn: używania parametrów w URL-ach (np. `?sessionid=123`), różnych wersji strony (HTTP/HTTPS, www/bez-www), czy wspomnianej już nawigacji fasetowej. Googlebot, napotykając takie duplikaty, musi je wszystkie odwiedzić i przeanalizować, aby zdecydować, którą wersję zaindeksować. To prowadzi do ogromnego marnotrawstwa budżetu, ponieważ zasoby są zużywane na indeksowanie treści, które już gdzieś widział.
Strony o niskiej wartości (Thin Content): Dlaczego Google nie chce ich odwiedzać?
Strony o niskiej wartości, często nazywane "thin content", to te, które dostarczają użytkownikowi niewielką lub żadną wartość dodaną. Mogą to być strony z automatycznie generowanymi opisami produktów, strony z minimalną ilością tekstu, strony z błędami, czy strony z powtarzającymi się komunikatami. Googlebot jest inteligentny i szybko rozpoznaje takie strony. Jeśli większość Twojej witryny składa się z takich zasobów, Googlebot zacznie je odwiedzać rzadziej, uznając je za nieefektywne wykorzystanie jego czasu. To obniża ogólny Crawl Demand dla Twojej strony.
Niekończące się przestrzenie: Jak paginacja i parametry w URL tworzą "czarne dziury" dla Googlebota?
Paginacja, czyli podział treści na wiele stron (np. wyniki wyszukiwania, artykuły blogowe), może stanowić wyzwanie. Jeśli linkowanie między stronami paginacji nie jest prawidłowo zaimplementowane (np. brak linku `rel="next"/"prev"` lub używanie parametrów w URL-ach), Googlebot może utknąć w nieskończonej pętli odwiedzania tych samych lub podobnych stron. Podobnie, niekontrolowane użycie parametrów w URL-ach (np. do śledzenia kampanii, identyfikatorów sesji) może generować ogromną liczbę wariantów tej samej strony, tworząc tzw. "czarne dziury" dla robotów, które pochłaniają budżet indeksowania.
Strategiczna optymalizacja Crawl Budget: Kompletny przewodnik krok po kroku
Po zidentyfikowaniu problemów, czas na ich rozwiązanie. Optymalizacja budżetu indeksowania to proces, który wymaga systematycznego podejścia i wdrożenia konkretnych działań. Oto kluczowe strategie, które możesz zastosować:
Fundament: Poprawa szybkości strony i czasu odpowiedzi serwera (TTFB)
Jak już wspomnieliśmy, szybkość ładowania strony i niski czas do pierwszego bajtu (Time To First Byte TTFB) są absolutnym fundamentem. Im szybciej Twój serwer odpowiada na żądania Googlebota, tym wyższy będzie jego Crawl Rate Limit. Aby to osiągnąć, skup się na:
- Optymalizacji obrazów: Kompresja, odpowiednie formaty (WebP), lazy loading.
- Wdrożeniu cache'owania: Zarówno po stronie serwera, jak i przeglądarki.
- Minifikacji kodu: CSS, JavaScript, HTML.
- Wybór wydajnego hostingu: Odpowiednia konfiguracja serwera.
- Wykorzystaniu sieci CDN (Content Delivery Network): Aby serwować treści z serwerów bliżej użytkownika.
Inteligentne zarządzanie plikiem robots. txt: Co blokować, by oszczędzać budżet?
Plik `robots.txt` to Twoja pierwsza linia obrony w zarządzaniu budżetem indeksowania. Używaj go strategicznie do blokowania dostępu Googlebota do zasobów, które nie mają wartości SEO lub które mogą marnować budżet:
- Strony logowania i panele administracyjne.
- Wyniki wewnętrznego wyszukiwania.
- Strony z duplikatami treści (jeśli nie można ich rozwiązać inaczej, np. tagiem kanonicznym).
- Strony z treściami o niskiej wartości (np. strony z podziękowaniami po zakupie, strony błędów).
Pamiętaj, że blokowanie w `robots.txt` zapobiega crawlowaniu, a tym samym bezpośrednio oszczędza budżet. Jest to skuteczniejsze niż dyrektywa `noindex` w tym kontekście.
Siła linków kanonicznych: Jak prawidłowo wskazywać oryginalne wersje podstron?
Tagi kanoniczne (`rel="canonical"`) są nieocenione w walce z duplikacją treści. Poprzez umieszczenie odpowiedniego znacznika w sekcji `
` strony, informujesz Googlebota, która wersja adresu URL jest tą preferowaną i powinna być indeksowana. Jest to szczególnie ważne w przypadku nawigacji fasetowej, paginacji czy stron z parametrami w URL-ach. Prawidłowo zastosowane linki kanoniczne pomagają Googlebotowi skupić się na indeksowaniu właściwych, wartościowych stron.Porządek w linkowaniu wewnętrznym: Ułatw robotom nawigację i wskaż priorytety
Dobrze zaplanowane linkowanie wewnętrzne jest jak mapa dla Googlebota. Upewnij się, że wszystkie ważne strony są łatwo dostępne poprzez linki z innych podstron. Strony, do których prowadzi najwięcej linków wewnętrznych (zwłaszcza z mocnych pozycji w nawigacji lub z treści artykułów), otrzymują wyższy priorytet w indeksowaniu (wyższy Crawl Demand). Unikaj tworzenia "martwych końców" i upewnij się, że linkujesz do kluczowych podstron z wielu miejsc.
Architektura informacji: Dlaczego płaska struktura strony wspiera lepsze indeksowanie?
Płaska architektura strony oznacza, że najważniejsze podstrony są dostępne w jak najmniejszej liczbie kliknięć od strony głównej. Zazwyczaj jest to 3-4 kliknięcia. Taka struktura ułatwia Googlebotowi dotarcie do wszystkich ważnych treści i efektywne ich indeksowanie. Unikaj głębokiego zagnieżdżania kategorii i podkategorii, które mogą sprawić, że bot będzie miał trudności z odkryciem wszystkich podstron.
Optymalizacja mapy witryny (sitemap. xml): Zadbaj, by zawierała tylko kluczowe adresy URL
Mapa witryny (`sitemap.xml`) jest dodatkowym sposobem na poinformowanie Google o strukturze Twojej strony. Upewnij się, że Twoja mapa witryny zawiera tylko te adresy URL, które faktycznie chcesz, aby Google zaindeksowało. Nie umieszczaj w niej stron zablokowanych w `robots.txt`, stron z błędami 404, przekierowaniami, czy stron o niskiej wartości. Zoptymalizowana mapa witryny pomaga Googlebotowi skupić się na tym, co najważniejsze.
Zarządzanie parametrami URL w Google Search Console: Kiedy warto z tego skorzystać?
W przeszłości Google Search Console oferowało narzędzie do zarządzania parametrami URL, które pozwalało instruować Googlebota, jak ma traktować określone parametry (np. czy parametr `color=red` tworzy nową stronę, czy jest tylko filtrem). Chociaż to narzędzie zostało z czasem wycofane, ogólna zasada pozostaje ważna: jeśli Twoja strona używa parametrów w URL-ach, które generują duplikaty, musisz zadbać o ich prawidłowe zarządzanie. Najczęściej rozwiązaniem jest odpowiednie użycie tagów kanonicznych lub blokowanie niechcianych wariantów w `robots.txt`.
Zaawansowane taktyki i najczęstsze mity dotyczące Crawl Budget
Świat SEO jest pełen mitów i nieporozumień. Omówmy kilka z nich, a także przyjrzyjmy się bardziej zaawansowanym podejściom do zarządzania budżetem indeksowania.
Mit 1: Zwiększenie częstotliwości publikacji zawsze poprawia crawl budget
Często słyszy się, że im więcej treści publikujemy, tym częściej Googlebot będzie odwiedzał naszą stronę. To nie do końca prawda. Owszem, świeże i wartościowe treści mogą zwiększyć Crawl Demand, ale jeśli zaczniemy masowo publikować niskiej jakości treści, duplikaty lub strony, które nie wnoszą nic nowego, Googlebot szybko to zauważy. Zamiast zwiększyć częstotliwość odwiedzin, może zacząć traktować naszą stronę jako źródło "śmieci", co negatywnie wpłynie na ogólny budżet. Jakość zawsze powinna być priorytetem nad ilością, szczególnie w kontekście crawl budget.
Mit 2: Dyrektywa "noindex" oszczędza budżet indeksowania
To częsty błąd. Dyrektywa `noindex` informuje Google, aby nie indeksował danej strony, ale nie zapobiega jej crawlowaniu. Oznacza to, że Googlebot nadal musi odwiedzić stronę, aby odczytać dyrektywę `noindex`. Jeśli chcesz faktycznie oszczędzić budżet indeksowania, czyli zasoby robota, którymi Googlebot mógłby odwiedzić inne, ważniejsze strony, powinieneś użyć blokady w pliku robots.txt dla stron, które nie powinny być w ogóle odwiedzane.
Przeczytaj również: Co to znaczy meta? Od greckich korzeni po Metaverse
Dobre praktyki: Jak zaplanować architekturę nowego serwisu z myślą o crawl budget?
Budowanie nowej strony od podstaw daje nam ogromną przewagę możemy od razu zaprojektować ją z myślą o efektywnym zarządzaniu budżetem indeksowania. Oto kilka kluczowych zasad:
- Czyste i semantyczne URL-e: Unikaj długich, skomplikowanych adresów z wieloma parametrami.
- Logiczna struktura nawigacji: Zaplanuj płaską architekturę, gdzie kluczowe treści są łatwo dostępne.
- Wysoka wydajność serwera: Wybierz hosting, który zapewni szybki czas odpowiedzi.
- Wstępna identyfikacja treści o niskiej wartości: Zastanów się, które typy stron mogą być problematyczne i jak im zapobiec (np. poprzez odpowiednie filtrowanie, blokowanie w `robots.txt`).
- Planowanie linkowania wewnętrznego: Już na etapie projektowania pomyśl, jak połączysz poszczególne sekcje strony.
Proaktywne podejście do crawl budget od samego początku budowy serwisu jest znacznie łatwiejsze i bardziej efektywne niż późniejsze naprawianie błędów w istniejącej, rozbudowanej witrynie.