
Googlebot to ogólna nazwa, którą określamy wszystkie roboty indeksujące (web crawlery) wykorzystywane przez wyszukiwarkę Google. Jego głównym zadaniem jest systematyczne przeszukiwanie zasobów internetu, aby odkrywać nowe i zaktualizowane treści. Bez tej nieustannej pracy, strony internetowe nie miałyby szansy pojawić się w wynikach wyszukiwania, a co za tym idzie dotrzeć do potencjalnych odbiorców. Wizyta Googlebota na Twojej stronie to zatem nie tylko techniczny proces, ale fundament Twojej widoczności online i, co za tym idzie, potencjalnego sukcesu biznesowego.
Często w kontekście przeszukiwania internetu używa się zamiennie terminów takich jak "robot", "pająk" czy "crawler". Wszystkie te określenia odnoszą się do tego samego mechanizmu programu komputerowego, który automatycznie przegląda strony internetowe, podążając za hiperłączami.
Pod maską Googlebota: Jak robot Google odkrywa, czyta i ocenia Twoją stronę krok po kroku
Działanie Googlebota, choć złożone, można podzielić na trzy kluczowe etapy. Zrozumienie każdego z nich jest niezbędne, aby móc świadomie zarządzać tym, jak wyszukiwarka postrzega naszą witrynę.
Krok 1: Crawling (odkrywanie) – podróż od linku do linku w poszukiwaniu nowych treści
Pierwszym etapem jest tak zwany crawling, czyli proces odkrywania. Googlebot rozpoczyna swoją podróż od listy znanych mu adresów URL, a następnie systematycznie odwiedza te strony. Kluczowe w tym procesie jest podążanie za linkami zarówno tymi wewnętrznymi, które łączą poszczególne podstrony w obrębie Twojej witryny, jak i zewnętrznymi, prowadzącymi do innych serwisów. W ten sposób bot odkrywa nowe zasoby, aktualizacje istniejących treści, a także buduje mapę powiązań między stronami w całym internecie. To właśnie od tego etapu zależy, czy Google w ogóle dowie się o istnieniu Twojej nowej podstrony.
Krok 2: Rendering (renderowanie) – dlaczego Google musi "zobaczyć" Twoją stronę jak użytkownik?
Po odkryciu strony, Googlebot przechodzi do etapu renderowania. W przeciwieństwie do prostych robotów, które jedynie odczytują kod HTML, Googlebot potrafi przetwarzać strony w sposób bardziej zbliżony do tego, jak robi to przeglądarka użytkownika. Oznacza to, że wykonuje kod JavaScript i analizuje strukturę CSS. Jest to niezwykle ważne, ponieważ pozwala Googlebotowi "zobaczyć" Twoją stronę tak, jak widzi ją przeciętny użytkownik z uwzględnieniem dynamicznych elementów, interaktywnych funkcji i odpowiedniego układu. Jakość renderowania ma bezpośredni wpływ na to, jak Google oceni treść i prezentację Twojej witryny.
Krok 3: Indexing (indeksowanie) – bilet wstępu do wielkiej biblioteki Google
Ostatnim, ale jakże kluczowym etapem jest indeksowanie. Po tym, jak Googlebot przeskanuje i zrenderuje stronę, jego algorytmy oceniają jej treść pod kątem wartości, jakości i trafności. Jeśli zawartość zostanie uznana za wartościową i użyteczną dla użytkowników, zostaje dodana do ogromnej bazy danych Google, zwanej indeksem. Można to porównać do dodania książki do wielkiej biblioteki. Tylko strony, które znajdą się w tym indeksie, mają szansę pojawić się w wynikach wyszukiwania, gdy użytkownik wpisze odpowiednie zapytanie. Bez indeksowania, Twoja strona po prostu nie istnieje dla wyszukiwarki.
Poznaj rodzinę Googlebotów: Który z nich odwiedza Twoją stronę i czego szuka?
Wspominając o Googlebocie, często myślimy o jednym, uniwersalnym robocie. W rzeczywistości jednak Google korzysta z całej rodziny wyspecjalizowanych botów, z których każdy ma swoje zadania i specyficzne cechy. Poznanie ich pozwala lepiej zrozumieć, jak optymalizować naszą witrynę pod kątem różnych potrzeb wyszukiwarki.
Googlebot Smartphone vs Desktop: Era Mobile-First Indexing w praktyce i co to oznacza dla Ciebie
Obecnie kluczową rolę odgrywa polityka Mobile-First Indexing. Oznacza to, że Google przede wszystkim analizuje i indeksuje wersję mobilną stron internetowych. W praktyce przekłada się to na to, że głównym "gościem" na Twojej stronie jest zazwyczaj Googlebot Smartphone, który symuluje zachowanie użytkownika korzystającego z telefonu komórkowego. Chociaż nadal istnieje Googlebot Desktop, jego znaczenie w procesie indeksowania maleje. Dla właścicieli stron oznacza to jedno: priorytetem powinna być doskonała optymalizacja mobilna responsywny design, szybkie ładowanie na urządzeniach mobilnych i czytelna treść na małym ekranie.
Wyspecjalizowani agenci: Googlebot-Image, -Video, -News i inni – jak ich zadowolić?
Oprócz głównego bota indeksującego, Google wykorzystuje również wyspecjalizowane roboty, które skupiają się na konkretnych typach treści:
- Googlebot Image: Odpowiedzialny za indeksowanie obrazów. Aby pomóc mu zrozumieć, co przedstawia Twoje zdjęcie, kluczowe jest stosowanie opisowych nazw plików i atrybutów `alt` (tekst alternatywny).
- Googlebot Video: Zajmuje się indeksowaniem treści wideo. Optymalizacja obejmuje tutaj m.in. dodawanie danych strukturalnych (schema.org) oraz transkrypcji.
- Googlebot News: Skupia się na indeksowaniu artykułów w sekcji Google News. Szybkość publikacji i zgodność ze wskazówkami dla wydawców są tutaj kluczowe.
- Istnieją również inne, mniej powszechne boty, np. do indeksowania produktów czy artykułów naukowych.
Każdy z tych botów ma swoje specyficzne wymagania, a ich zadowolenie przekłada się na lepszą widoczność w dedykowanych sekcjach wyszukiwarki.
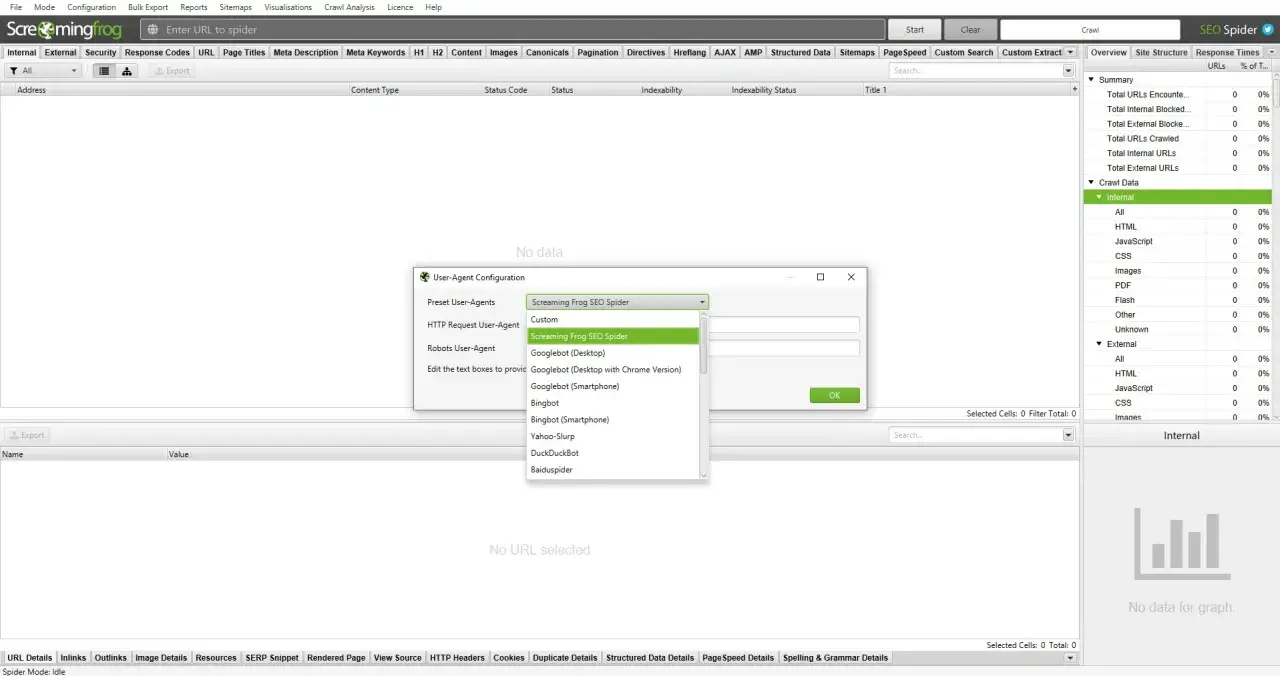
User-Agent: Jak rozpoznać, który Googlebot odwiedził Twoją witrynę?
Każdy program odwiedzający Twoją stronę internetową wysyła do serwera tzw. nagłówek User-Agent. Jest to ciąg znaków identyfikujący przeglądarkę lub bota. Analizując logi serwera, możesz precyzyjnie określić, który konkretnie Googlebot odwiedził Twoją witrynę. Przykładowo, dla Googlebot Smartphone User-Agent może wyglądać tak: Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html). Rozpoznanie User-Agenta jest pierwszym krokiem do zrozumienia, jakie treści bot indeksuje i jak może postrzegać Twoją stronę.

Budżet indeksowania (Crawl Budget): Dlaczego Google nie skanuje całej Twojej strony od razu?
W przypadku dużych i złożonych witryn, takich jak rozbudowane portale informacyjne czy sklepy internetowe z tysiącami produktów, pojawia się zagadnienie, które nazywamy budżetem indeksowania, czyli crawl budget. Jest to niezwykle ważna koncepcja, która bezpośrednio wpływa na efektywność, z jaką Googlebot odwiedza i indeksuje Twoją stronę.
Czym jest budżet na indeksowanie i dlaczego jest kluczowy dla dużych portali i sklepów?
Budżet indeksowania to, najprościej mówiąc, ograniczona liczba zasobów (czasu i mocy obliczeniowej), które Googlebot może przeznaczyć na przeskanowanie Twojej witryny w określonym czasie. Google nie chce nadmiernie obciążać serwerów właścicieli stron, ani marnować własnych zasobów na strony, które rzadko się zmieniają lub są niskiej jakości. Dla dużych portali i sklepów internetowych jest to kluczowe, ponieważ efektywne wykorzystanie budżetu decyduje o tym, jak szybko nowe artykuły, produkty czy aktualizacje pojawią się w indeksie Google. Jeśli budżet jest źle zarządzany, nowe treści mogą czekać na zaindeksowanie bardzo długo, co negatywnie wpływa na ich widoczność.
Co "zjada" Twój budżet? Najczęstsze problemy techniczne marnujące zasoby bota
Istnieje wiele czynników, które mogą niepotrzebnie zużywać Twój budżet indeksowania, prowadząc do marnowania cennych zasobów Googlebota. Do najczęstszych należą:
- Błędy 404 (Not Found): Linki prowadzące do nieistniejących stron. Bot marnuje czas, próbując je odwiedzić.
- Nieskończone pętle przekierowań: Gdy strona przekierowuje sama do siebie lub w cyklu.
- Powielona treść: Wersje tej samej strony dostępne pod różnymi adresami URL.
- Wolne ładowanie strony: Bot musi czekać na odpowiedź serwera, co pochłania jego czas.
- Niepotrzebne strony z parametrami: Strony generowane dynamicznie przez parametry URL, które nie wnoszą unikalnej wartości.
- Nadmierne użycie JavaScript: Jeśli renderowanie strony zajmuje botowi zbyt dużo czasu.
Każdy z tych problemów sprawia, że Googlebot spędza czas na tym, czego nie powinien, zamiast skupić się na indeksowaniu wartościowych treści.
Jak sprawdzić i zoptymalizować budżet indeksowania, by Google odwiedzał Cię częściej?
Optymalizacja budżetu indeksowania to proces ciągły, ale przynoszący wymierne korzyści. Oto kilka praktycznych kroków:
- Poprawa szybkości ładowania strony: Optymalizacja obrazów, kodu, wykorzystanie pamięci podręcznej (cache).
- Eliminacja błędów: Regularne sprawdzanie i naprawianie błędów 404, 5xx oraz problemów z przekierowaniami.
- Zarządzanie powieloną treścią: Używanie tagów kanonicznych (`rel="canonical"`) lub przekierowań 301.
- Używanie pliku robots.txt: Blokowanie dostępu do nieistotnych sekcji witryny (np. strony logowania, koszyka, wyników wyszukiwania wewnętrznego), które nie powinny być indeksowane.
- Aktualizacja mapy witryny (sitemap.xml): Upewnij się, że mapa zawiera tylko ważne, aktualne adresy URL.
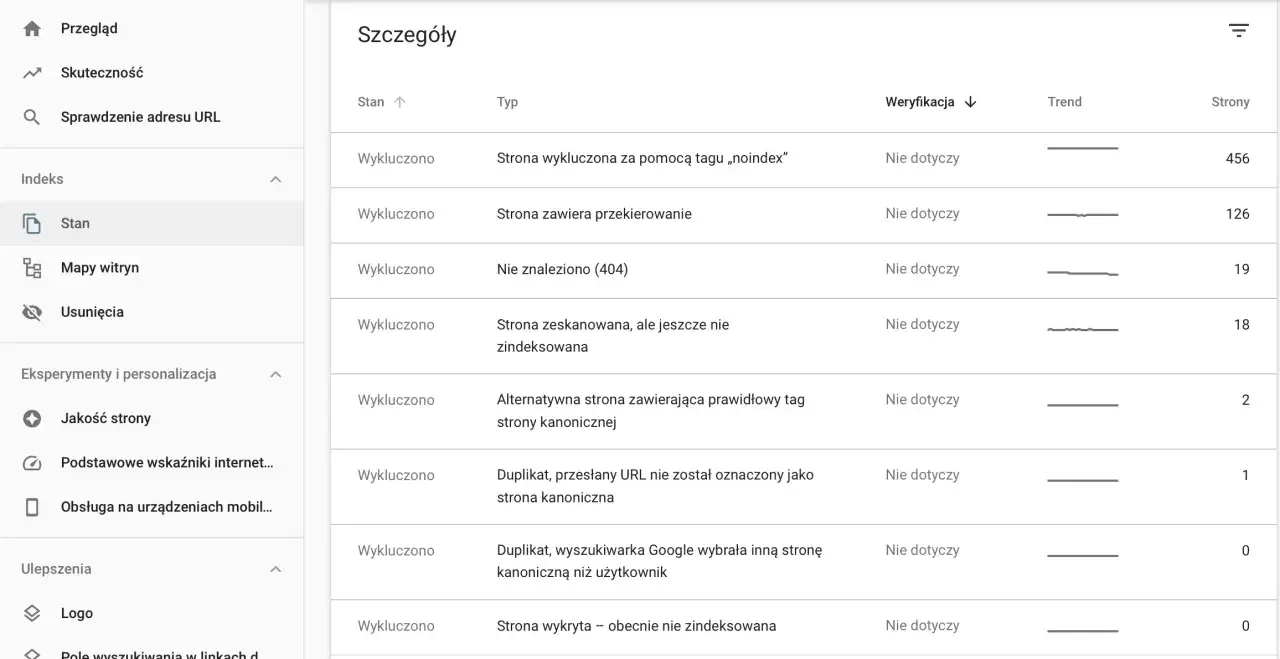
- Monitorowanie w Google Search Console: Narzędzie "Stan indeksowania" oraz raporty dotyczące błędów mogą dostarczyć cennych wskazówek.
Dzięki tym działaniom sprawisz, że Googlebot będzie efektywniej wykorzystywał swój budżet, co przełoży się na szybsze i lepsze indeksowanie Twojej witryny.
Twoja strona, Twoje zasady: Jak świadomie zarządzać i kontrolować wizyty Googlebota?
Choć Googlebot działa autonomicznie, jako właściciele stron internetowych mamy do dyspozycji szereg narzędzi i metod, które pozwalają nam wpływać na jego zachowanie. Świadome zarządzanie wizytami bota jest kluczowe dla utrzymania porządku w indeksie wyszukiwarki i zapewnienia, że tylko pożądane treści są widoczne dla użytkowników.
Plik robots.txt: Podstawowy komunikator z robotami – jak go poprawnie skonfigurować?
Plik robots.txt to prosty plik tekstowy umieszczany w głównym katalogu witryny (np. `twojadomena.pl/robots.txt`). Jest to podstawowy mechanizm komunikacji z robotami wyszukiwarek, w tym z Googlebotem. Pozwala on na określenie, które części Twojej strony roboty mogą, a które nie powinny odwiedzać i indeksować. Jest to szczególnie przydatne do blokowania dostępu do sekcji, które nie mają wartości dla wyszukiwarki, np. strony administracyjne, wyniki wyszukiwania wewnętrznego, czy strony z powieloną treścią. Pamiętaj jednak, że robots.txt informuje, nie wymusza złośliwe boty mogą go ignorować. Poprawna składnia wygląda na przykład tak:
User-agent: Googlebot
Disallow: /prywatne/
Disallow: /admin/
Powyższy przykład informuje Googlebota, aby nie wchodził na podstrony znajdujące się w katalogach `/prywatne/` i `/admin/`.
Meta tagi "noindex" i "nofollow": Precyzyjne instrukcje dla Google na poziomie pojedynczej strony
Oprócz pliku robots.txt, który działa na poziomie całej witryny lub jej sekcji, istnieją również meta tagi, które pozwalają na precyzyjne instrukcje dotyczące konkretnych podstron. Najważniejsze z nich to:
- `noindex`: Ten meta tag, umieszczony w sekcji `` kodu HTML strony, informuje Google, aby nie indeksował danej strony. Oznacza to, że nawet jeśli bot ją odwiedzi, nie doda jej do swojego indeksu i nie będzie ona widoczna w wynikach wyszukiwania. Jest to przydatne dla stron, które istnieją tylko dla celów nawigacyjnych lub technicznych, a nie dla użytkowników.
- `nofollow`: Ten tag, stosowany zarówno w meta tagach robots, jak i jako atrybut linku (`rel="nofollow"`), instruuje Google, aby nie podążał za linkami znajdującymi się na tej stronie (lub konkretnym linkiem). Jest to często używane w komentarzach lub na stronach z dużą liczbą linków partnerskich, aby zapobiec przekazywaniu "mocy" SEO na inne strony.
Przykład użycia w kodzie HTML:
Mapa witryny (sitemap.xml): Stwórz drogowskaz dla Googlebota, by niczego nie pominął
Mapa witryny, czyli plik sitemap.xml, jest niczym szczegółowy drogowskaz dla Googlebota. Zawiera listę wszystkich ważnych adresów URL Twojej witryny, wraz z dodatkowymi informacjami, takimi jak data ostatniej modyfikacji czy priorytet. Jest to niezwykle pomocne dla Googlebota, zwłaszcza w przypadku dużych stron lub stron z nową treścią, do której trudno dotrzeć poprzez standardowe linkowanie wewnętrzne. Dobrze przygotowana i regularnie aktualizowana mapa witryny zapewnia, że Googlebot odkryje wszystkie kluczowe podstrony i będzie wiedział, które z nich są najczęściej aktualizowane. Należy pamiętać, aby zgłosić swoją mapę witryny w narzędziu Google Search Console.Google Search Console: Twoje centrum dowodzenia ruchem i statystykami botów
Google Search Console (GSC) to absolutnie fundamentalne narzędzie dla każdego właściciela strony internetowej. Działa ono jako centrum dowodzenia, które pozwala na monitorowanie interakcji Googlebota z Twoją witryną. W GSC możesz:
- Monitorować stan indeksowania: Sprawdzić, ile stron zostało zaindeksowanych, a ile napotkało błędy.
- Zgłaszać mapę witryny: Ułatwić botowi odkrywanie Twoich treści.
- Analizować dane o ruchu: Zrozumieć, jakie zapytania prowadzą użytkowników na Twoją stronę.
- Sprawdzać, jak Googlebot "widzi" Twoją stronę: Narzędzie "Pokaż jako Google" pozwala zobaczyć, jak Googlebot renderuje Twoją stronę.
- Identyfikować i naprawiać błędy: GSC informuje o problemach technicznych, które mogą wpływać na indeksowanie.
Gdy Googlebot staje się problemem: Najczęstsze błędy i jak sobie z nimi radzić
Chociaż zazwyczaj chcemy, aby Googlebot jak najczęściej odwiedzał nasze strony, czasami jego aktywność może generować problemy. Zrozumienie, jak odróżnić prawdziwego bota od oszusta i jak radzić sobie z niepożądanymi zachowaniami, jest równie ważne, jak zachęcanie go do odwiedzin.
Jak sprawdzić w logach serwera, czy to prawdziwy Googlebot, a nie oszust?
Weryfikacja autentyczności Googlebota jest kluczowa, zwłaszcza gdy zauważasz nietypowo duży ruch lub podejrzane zachowania. Podszywające się programy (tzw. "bad bots") mogą marnować Twój budżet indeksowania, a nawet próbować wykorzystać luki w zabezpieczeniach. Aby sprawdzić, czy ruch pochodzi od prawdziwego Googlebota, wykonaj dwa kroki:
- Sprawdź nagłówek User-Agent: Jak wspomniano wcześniej, prawdziwy Googlebot wysyła specyficzny User-Agent. Upewnij się, że jest zgodny z oficjalnymi wytycznymi Google.
- Wykonaj odwrotne wyszukiwanie DNS (Reverse DNS lookup): Adres IP, z którego pochodzi ruch, powinien należeć do infrastruktury Google. Możesz to sprawdzić za pomocą narzędzi online lub linii komend, wpisując adres IP i sprawdzając, czy jego nazwa hosta kończy się na `googlebot.com` lub `google.com`.
Połączenie tych dwóch weryfikacji daje wysoki stopień pewności, że masz do czynienia z autentycznym robotem Google.
Moja strona ładuje się wolno przez Googlebota – jak ograniczyć częstotliwość jego wizyt?
Jeśli zauważasz, że strona znacząco zwalnia podczas intensywnych wizyt Googlebota, może to być sygnał, że bot próbuje uzyskać dostęp do zbyt wielu zasobów naraz, lub że serwer nie radzi sobie z obciążeniem. Chociaż Google stara się nie nadwyrężać serwerów, istnieją sposoby, aby zarządzać częstotliwością jego wizyt:
- Optymalizacja serwera: Upewnij się, że Twój hosting jest wystarczająco wydajny.
- Poprawa szybkości ładowania strony: Szybsze ładowanie oznacza, że bot potrzebuje mniej czasu na pobranie strony, co może pośrednio wpłynąć na częstotliwość jego powrotów.
- Użycie pliku robots.txt: Zablokowanie dostępu do mniej ważnych sekcji może skierować bota na te bardziej wartościowe, ale niekoniecznie zwiększy to jego ogólną częstotliwość wizyt.
- Google Search Console (ograniczone możliwości): W niektórych przypadkach, w Google Search Console można znaleźć opcję ustawienia "Częstotliwość skanowania", jednak Google często sam dostosowuje ten parametr w zależności od stanu witryny i jej aktualizacji.
Najskuteczniejszym rozwiązaniem jest zazwyczaj poprawa ogólnej wydajności strony i serwera.
Przeczytaj również: Szukaj zdjęciem - Jak to zrobić na PC i smartfonie? Poradnik
Błędy indeksowania, które sabotują Twoje SEO (i jak je naprawić w Google Search Console)
Błędy indeksowania to jedni z największych sabotażystów SEO. Mogą one sprawić, że wartościowe treści nigdy nie trafią do indeksu lub zostaną usunięte. Oto najczęstsze problemy i sposoby ich naprawy w Google Search Console:
-
Błędy 404 (Nie znaleziono):
- Problem: Linki prowadzą do nieistniejących stron.
- Naprawa: Znajdź i napraw uszkodzone linki w swojej witrynie lub skonfiguruj przekierowania 301 na poprawne adresy.
-
Błędy serwera (np. 5xx):
- Problem: Problemy z działaniem serwera uniemożliwiające dostęp do strony.
- Naprawa: Skontaktuj się z dostawcą hostingu, aby rozwiązać problemy z serwerem.
-
Problemy z dostępem do robots.txt:
- Problem: Googlebot nie może uzyskać dostępu do pliku robots.txt lub jest on nieprawidłowo skonfigurowany.
- Naprawa: Upewnij się, że plik robots.txt jest dostępny pod głównym adresem domeny i nie blokuje przypadkowo ważnych zasobów.
-
Brak renderowania lub problemy z JavaScript:
- Problem: Googlebot nie jest w stanie poprawnie przetworzyć zawartości strony, np. z powodu błędów w kodzie JavaScript.
- Naprawa: Użyj narzędzia "Pokaż jako Google" w GSC, aby zdiagnozować problemy z renderowaniem i poprawić kod strony.
-
Strony z przekierowaniem:
- Problem: Zbyt długie lub błędne łańcuchy przekierowań.
- Naprawa: Uprość strukturę przekierowań, stosuj bezpośrednie przekierowania 301.
Regularne monitorowanie raportu "Stan indeksowania" w Google Search Console i szybkie reagowanie na pojawiające się błędy jest kluczowe dla utrzymania wysokiej pozycji w wynikach wyszukiwania.