W praktyce widzę, że wiele problemów z widocznością nie wynika z samego tekstu, tylko z tego, jak serwis rozprowadza sygnał między stronami. PageRank jest właśnie takim mechanizmem: pomaga ocenić ważność dokumentów na podstawie linków, ale nie zastępuje indeksacji ani sensownej architektury treści. W tym artykule rozkładam temat na czynniki pierwsze i pokazuję, co faktycznie warto poprawić w blogu, sklepie albo portalu technologicznym.
Najważniejsze rzeczy o linkach, indeksacji i widoczności
- PageRank ocenia wagę strony na podstawie linków, ale sam nie sprawi, że URL trafi do indeksu.
- Do przekazania sygnału potrzebujesz
, sensownego anchor textu i logicznej struktury linków wewnętrznych. -
noindexusuwa stronę z indeksu, arobots.txtblokuje crawl. To dwa różne narzędzia. - Mapa witryny pomaga odkrywać adresy, ale nie gwarantuje indeksacji ani lepszej pozycji.
- Na większych serwisach największe straty robią duplikaty URL, filtry, osierocone podstrony i długie łańcuchy przekierowań.
Czym jest PageRank i dlaczego nadal ma znaczenie
Najprościej ujmując, PageRank traktuje linki jak głosy zaufania, ale nie każdy głos ma tę samą wagę. Strona linkowana z mocnego, dobrze osadzonego tematycznie materiału zwykle zyskuje więcej niż podstrona, do której prowadzi przypadkowy odnośnik z bocznego archiwum. Google Search Central wprost wskazuje, że to jeden z podstawowych systemów rankingowych od startu wyszukiwarki, choć sam mechanizm mocno się zmienił.
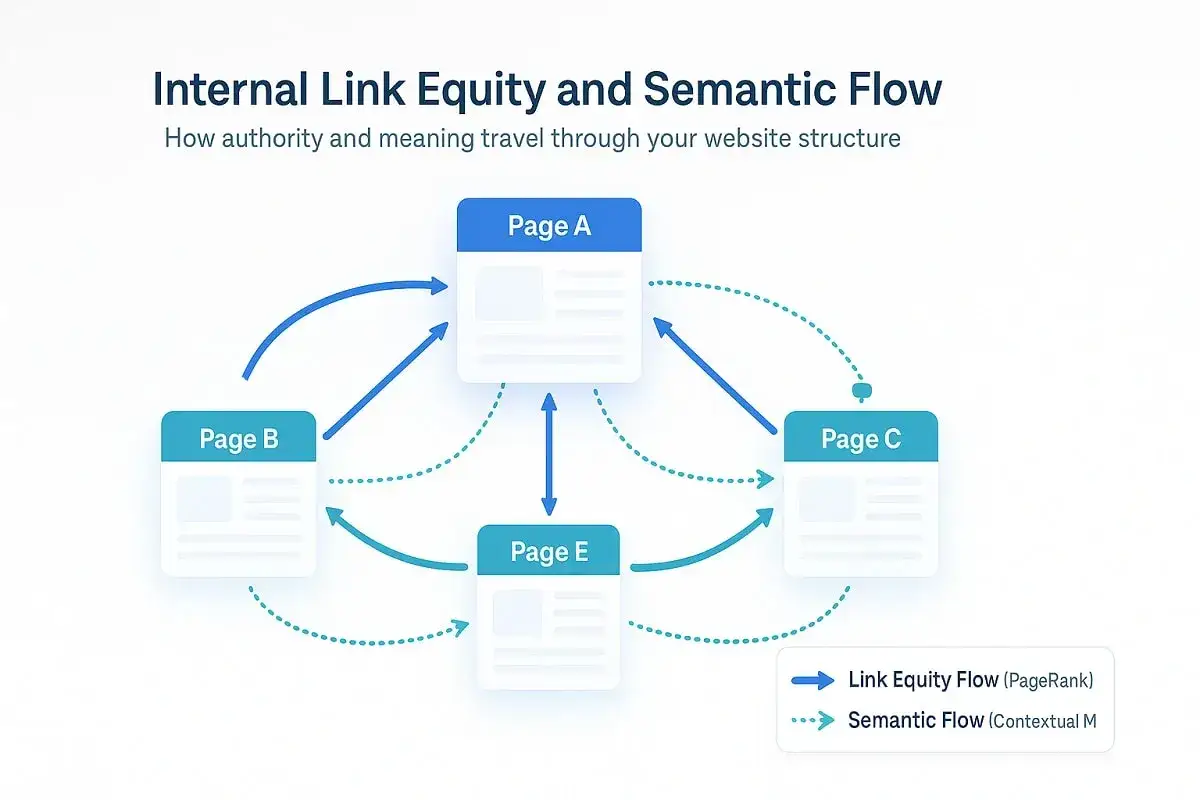
W praktyce oznacza to, że nie liczy się wyłącznie liczba linków. Ważne są też kontekst, struktura serwisu i to, czy dana podstrona w ogóle ma szansę być odkryta oraz poprawnie zrozumiana przez crawlera. Ja najczęściej rozdzielam ten temat na dwie warstwy: siłę sygnału linkowego i zdolność strony do wejścia do indeksu. To dobry moment, żeby przejść od teorii do tego, jak linki faktycznie pracują w codziennym SEO.
Jak linki przekazują sygnał w serwisie
Jeżeli mam wskazać jeden obszar, który najczęściej daje szybki efekt, to jest nim właśnie linkowanie wewnętrzne. Google wykorzystuje linki zarówno do odkrywania nowych stron, jak i do oceny ich relacji z resztą serwisu, więc źle ułożona siatka odnośników potrafi osłabić nawet bardzo dobry content.
W praktyce nie warto traktować nofollow jak magicznego bezpiecznika. Używa się go wtedy, gdy naprawdę nie chcesz wzmacniać konkretnego odnośnika, a nie po to, by „uprzejmie” przykryć każdy link zewnętrzny. Z kolei przy migracjach domen Google zwraca uwagę, że sygnały rankingowe, w tym PageRank, przechodzą przez 301, więc skracanie łańcuchów przekierowań ma bardzo konkretne znaczenie. Jeśli ten przepływ działa, łatwiej też odróżnić sygnał rankingowy od samej indeksacji, a to w SEO robi ogromną różnicę.
Dlaczego indeksacja i ranking to różne rzeczy
Tu najłatwiej o pomyłkę: PageRank działa na etapie rankingu, a nie samego odkrycia strony. Ja rozdzielam temat na trzy kroki: odkrycie adresu, pobranie go przez robota i dopiero potem ocenę w indeksie. Jeśli któryś krok się wysypie, moc linków nie uratuje widoczności.
- Odkrycie - Google musi w ogóle dowiedzieć się, że adres istnieje, najczęściej przez link albo mapę witryny.
- Crawl - bot pobiera stronę i sprawdza, co naprawdę się na niej znajduje.
- Indeks i ranking - dopiero wtedy treść może być oceniona na tle innych wyników.
Google Search Central przypomina też, że mapa witryny może pomóc w odkrywaniu serwisu, ale nie gwarantuje indeksacji ani lepszej pozycji. To ważne, bo zbyt często widzę sytuację, w której ktoś wysyła sitemapę, a potem oczekuje, że problem widoczności sam się rozwiąże. Nie rozwiąże, jeśli strona jest blokowana przez robots.txt, ma konflikt między noindex i canonicalem albo ukrywa kluczową treść za interakcją, której crawler nie odtworzy w pełni. W modelu mobile-first dochodzi jeszcze jakość wersji mobilnej: jeśli skracasz treść albo opierasz ją na kliknięciu użytkownika, robot może zobaczyć mniej, niż zakładasz.
Gdy patrzę na serwis od strony indeksacji, pytam najpierw nie „jak go wzmocnić”, tylko „czy on w ogóle jest czytelny dla Google”. Dopiero potem zaczyna się sensowna praca nad linkami i strukturą. To prowadzi nas do najbardziej praktycznej części całego tematu.
Jak uporządkować serwis, żeby ważne podstrony rosły szybciej
Na dużych serwisach, zwłaszcza tam, gdzie są filtry, tagi, archiwa i wersje sortowania, sygnał linkowy rozmywa się najłatwiej. Nie trzeba tu cudów, tylko porządku: ograniczenia duplikatów, lepszego linkowania z poziomu serwisu i pilnowania, by ważne strony nie były odseparowane od reszty.
| Problem | Co się dzieje | Co robię w praktyce |
|---|---|---|
| Strony osierocone | Robot może ich nie znaleźć albo odwiedzać je rzadko. | Linkuję je z hubów tematycznych, kategorii i powiązanych artykułów. |
| Parametry i filtry | Powstaje lawina wariantów tego samego contentu. | Porządkuję URL-e, stosuję canonicale i ograniczam indeksację śmieciowych kombinacji. |
| Zbyt głęboka struktura | Ważne treści są zbyt daleko od strony głównej. | Skracam ścieżkę kliknięć, dodaję breadcrumbs i sekcje tematyczne. |
| Łańcuchy przekierowań | Tracisz czas crawl'a i rozmywasz sygnał. | Prowadzę linki od razu do adresu docelowego i porządkuję stare odnośniki. |
| Cienkie archiwa i tagi | Powtarzalne strony konkurują z właściwymi materiałami. | Konsoliduję je albo ograniczam ich indeksację, jeśli nie wnoszą wartości. |
404 lub 410 niż kolejny poziom przekierowania. Gdy ta architektura jest czysta, łatwiej zobaczyć, które błędy naprawdę zabijają sygnał linkowy, a które tylko wyglądają groźnie w raportach.
Najczęstsze błędy, które rozbijają sygnał linków
W audytach widzę wciąż te same potknięcia: nie są spektakularne, ale skutecznie rozpraszają sygnał i utrudniają indeksację. Najgorsze jest to, że część z nich wygląda „technicznie poprawnie” na pierwszy rzut oka, więc łatwo je przeoczyć.
- Linki bez
hrefalbo nawigacja oparta wyłącznie na skryptach - crawler może nie wydobyć adresu i strona zostaje słabiej odkryta. - Globalne
nofollowna linkach wewnętrznych - zamiast porządkować sygnał, potrafi go po prostu osłabić. - Strony osierocone - istnieją w CMS, ale nie prowadzi do nich żaden sensowny link z serwisu.
- Konflikt między
canonical,noindexirobots.txt- wtedy bot dostaje sprzeczne instrukcje i trudniej przewidzieć efekt. - Duplikaty tworzone przez sortowanie, filtry, parametry i wersje wydruku - każdy dodatkowy wariant odbiera uwagę adresowi właściwemu.
- Długie łańcuchy
301oraz naprawiane po latach błędy 404 - sygnał się rozprasza, a crawl staje się mniej efektywny.
Jest jeszcze jeden błąd, który wraca regularnie: traktowanie linków zewnętrznych jak zagrożenia samego w sobie. Dobrze dobrany odnośnik do źródła, narzędzia albo dokumentacji nie osłabia tekstu, tylko go uwiarygadnia. Ważne, by był sensowny i osadzony w kontekście, a nie wciśnięty po to, żeby „odhaczyć SEO”. Jeśli chcesz przejść od błędów do działania, ostatnia rzecz jest najważniejsza: zacznij od diagnozy, nie od przypadkowego przepisywania linków.
Co sprawdzić w audycie, zanim ruszysz z contentem
Gdybym miał zrobić szybki audyt, zacząłbym od pięciu rzeczy: stron osieroconych, wewnętrznych odnośników z mocnych sekcji, konfliktów w meta robots i canonicalach, duplikatów URL oraz raportu indeksowania w Search Console. To zwykle wystarcza, żeby odróżnić problem linkowy od problemu stricte indeksacyjnego. W serwisie technologicznym taki porządek ma jeszcze jedną zaletę: pomaga szybciej wynosić do widoczności treści eksperckie, a nie tylko najnowsze publikacje.
Jeśli miałbym wybrać jedną zasadę, byłaby prosta: najpierw sprawdź, czy Google w ogóle może znaleźć i zrozumieć adres, a dopiero potem wzmacniaj go linkami. Właśnie w tej kolejności PageRank zaczyna pracować na korzyść serwisu, zamiast ginąć w bałaganie architektury.