SEO to zestaw działań, które pomagają wyszukiwarce odnaleźć stronę, zrozumieć jej treść i uznać ją za wartą pokazania użytkownikowi. Sama widoczność nie zaczyna się jednak od pozycji w Google, tylko od tego, czy podstrona w ogóle trafi do indeksu. Poniżej rozkładam to na proste elementy: czym jest SEO, jak działa indeksacja, co ją blokuje i co realnie warto poprawić najpierw.
Najważniejsze rzeczy o SEO i indeksacji w skrócie
- SEO pomaga wyszukiwarce znaleźć, zrozumieć i ocenić treść, ale bez indeksacji nie ma mowy o widoczności.
- Google nie gwarantuje, że każda odkryta strona trafi do indeksu, a sam proces może zająć od kilku dni do kilku tygodni.
- `noindex` blokuje indeksację, a `robots.txt` najczęściej blokuje samo crawlowanie, więc to dwa różne problemy.
- Największą różnicę robią: dobra struktura serwisu, sensowne linkowanie wewnętrzne, poprawne nagłówki i techniczny porządek.
- W Search Console najszybciej sprawdzam status indeksacji, błędy i to, czy Google w ogóle widzi najważniejsze adresy.
Czym jest SEO i gdzie kończy się indeksacja
Ja patrzę na SEO jak na trzy powiązane etapy: wyszukiwarka musi najpierw znaleźć stronę, potem ją przeczytać, a dopiero na końcu zdecydować, czy i jak ją pokazać użytkownikowi. To dlatego sama optymalizacja treści nie wystarczy, jeśli serwis jest słabo dostępny technicznie albo ważne podstrony nie są w ogóle indeksowane.
Google Search Central opisuje SEO jako sposób na ułatwienie wyszukiwarkom crawlowania, indeksowania i rozumienia treści. W praktyce oznacza to, że SEO nie kończy się na słowach kluczowych - obejmuje też architekturę serwisu, jakość HTML, linkowanie i techniczne sygnały, które pomagają botom zrozumieć, co jest ważne. Strona może być zaindeksowana, a mimo to nie zbierać ruchu, jeśli przegrywa z konkurencją jakością, trafnością albo strukturą informacji.
| Etap | Co się dzieje | Dlaczego ma znaczenie |
|---|---|---|
| Crawling | Bot odkrywa i pobiera adres URL. | Bez tego Google nie zobaczy treści strony. |
| Indexing | Treść trafia do bazy wyszukiwarki. | Tylko zaindeksowana strona może pojawić się w wynikach. |
| Ranking | Systemy wyszukiwarki ustalają kolejność wyników. | Dopiero tutaj walczysz o kliknięcie i pozycję. |
To rozróżnienie jest ważne, bo bez niego łatwo leczyć zły problem. Jeśli strona nie jest w indeksie, nie ma sensu zaczynać od upiększania nagłówków; najpierw trzeba sprawdzić, jak Google w ogóle dociera do treści.
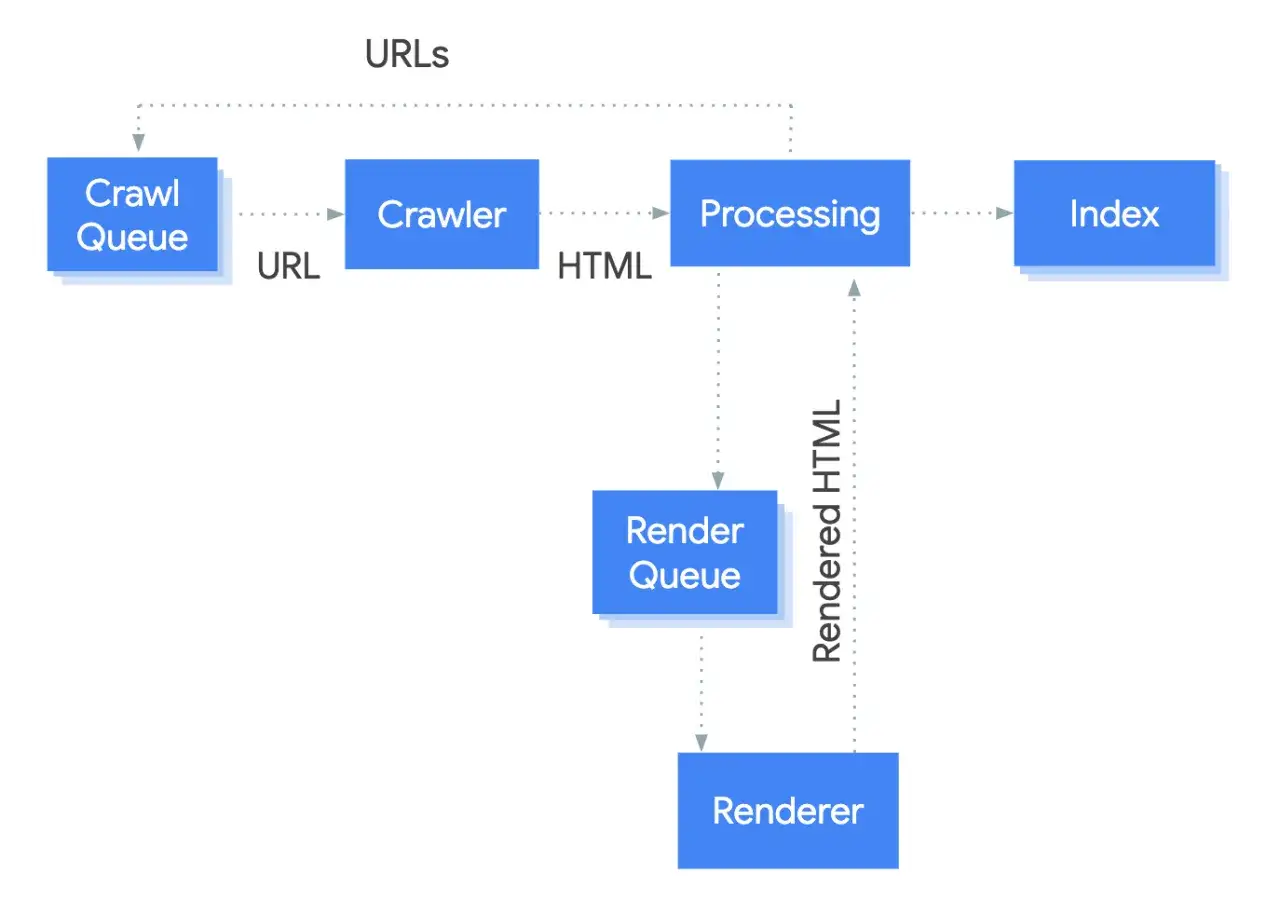
Jak Google odkrywa, crawluje i indeksuje stronę
W praktyce Google zwykle trafia na nowy adres przez link wewnętrzny, link zewnętrzny albo mapę witryny. Potem pobiera HTML, analizuje zasoby, sprawdza, czy treść jest dostępna na urządzeniach mobilnych, a następnie ocenia, czy URL warto dodać do indeksu. Search Console pozwala zgłosić adres do ponownego crawlowania, ale to nadal prośba, nie gwarancja.
Od odkrycia strony do jej indeksacji może minąć kilka dni, a przy większych serwisach nawet kilka tygodni. W Google Search Central podkreśla się też, że crawlowanie i indeksowanie nie są automatyczną obietnicą dla każdego URL-a, więc sam fakt publikacji nie oznacza jeszcze widoczności.
| Co robi Google | Co pomaga | Co najczęściej przeszkadza |
|---|---|---|
| Odkrywa URL | Linki wewnętrzne, mapa witryny, logiczna architektura. | Osierocone podstrony bez żadnych linków prowadzących do nich. |
| Pobiera treść | Czysty HTML, szybka odpowiedź serwera, poprawne zasoby. | `robots.txt`, błędy 4xx/5xx, ciężki JavaScript. |
| Ocenia wartość | Unikalna, kompletna treść i sensowny kontekst tematyczny. | Cienkie strony, duplikaty, automatycznie generowane bloki bez wartości. |
Kiedy ten łańcuch się zrywa, zwykle winne są proste blokady techniczne, które da się sprawdzić bez zgadywania. I właśnie na nie patrzę najpierw, zanim zacznę szukać bardziej złożonych przyczyn.
Co najczęściej blokuje indeksację
Najczęściej problem nie polega na jednym spektakularnym błędzie, tylko na kilku drobnych przeszkodach naraz. W praktyce widzę to bardzo często: strona ma `noindex`, słabe linkowanie i mało treści, a potem pojawia się zdziwienie, że Google nie chce jej pokazać. To nie jest kaprys wyszukiwarki, tylko normalny efekt sygnałów, które dostała.
| Blokada | Co oznacza w praktyce | Jak to naprawić |
|---|---|---|
| `noindex` w meta tagu lub nagłówku `X-Robots-Tag` | Google może pobrać stronę, ale nie doda jej do indeksu. | Usuń tag, jeśli strona ma być widoczna w wynikach. |
| `robots.txt` blokujący crawlowanie | Bot nie może w ogóle pobrać treści. | Odblokuj dostęp dla adresów, które mają być widoczne. |
| Zły `canonical` | Google uznaje inną wersję strony za właściwą. | Ustaw canonical na adres, który naprawdę chcesz indeksować. |
| Osierocona podstrona | Nikt do niej nie linkuje, więc trudno ją odkryć. | Dodaj linki z już indeksowanych sekcji serwisu. |
| Cienka lub duplikowana treść | Strona nie daje wystarczająco mocnego powodu do indeksacji. | Rozbuduj materiał, scal podobne strony albo usuń duble. |
| Problemy z renderowaniem JavaScriptu | Google widzi tylko część treści albo widzi ją z opóźnieniem. | Zapewnij krytyczny content w HTML lub w modelu przyjaznym dla crawla. |
| Słaba wersja mobilna | Google indeksuje przede wszystkim wersję mobilną strony. | Ujednolić treść i funkcje między desktopem a mobilem. |
Tu jest mało miejsca na domysły: albo strona jest dostępna, logicznie połączona i wartościowa, albo nie. Gdy techniczne bariery znikną, dopiero wtedy sensownie widać, czy problem leży w treści, strukturze albo w samej strategii SEO.
Jakie działania SEO dają najlepszy efekt na starcie
Na nowej stronie nie próbuję robić wszystkiego naraz. Zamiast tego ustawiam priorytety tak, żeby wyszukiwarka miała łatwą drogę do najważniejszych podstron, a użytkownik szybko widział, że treść jest uporządkowana i kompletna. To zwykle daje lepszy efekt niż rozproszone poprawki bez planu.
- Porządkuję architekturę informacji - najpierw kategorie, sekcje i powiązania między treściami, dopiero potem pojedyncze detale.
- Nadaję stronie jeden główny temat - każda podstrona powinna odpowiadać na konkretną intencję, a nie próbować zadowolić wszystkich naraz.
- Poprawiam tytuły, leady i nagłówki - bot i czytelnik muszą od razu zrozumieć, o czym jest materiał.
- Dodaję sensowne linki wewnętrzne - najlepiej z miejsc, które Google już regularnie crawluje.
- Sprawdzam sitemapę, canonicale i robots - to drobiazgi, które potrafią zablokować całą sekcję serwisu.
- Używam danych strukturalnych tam, gdzie mają sens - nie dla ozdoby, tylko po to, by lepiej opisać typ treści.
Na portalu technologicznym i AI szczególnie dobrze działa porządek tematyczny: jeden mocny artykuł główny, kilka powiązanych rozwinięć i jasna hierarchia linków. Taki układ zwykle daje więcej niż przypadkowe produkowanie podobnych tekstów, bo wzmacnia zarówno indeksację, jak i rozumienie całego klastra treści. Ale żeby nie żyć w domysłach, trzeba jeszcze umieć odczytać dane.
Jak sprawdzam, czy strona naprawdę rośnie w Google
Ja zaczynam od Google Search Console, bo to najszybszy sposób, żeby oddzielić problem indeksacji od problemu z rankingiem. Jeśli podstrony są w indeksie, ale nie ma wrażeń ani kliknięć, to zwykle nie walczę już z techniką, tylko z dopasowaniem treści do intencji albo z przewagą konkurencji.
- Raport Page Indexing - pokazuje, które adresy są zaindeksowane, a które odrzucone i dlaczego.
- URL Inspection - pozwala sprawdzić konkretną podstronę tak, jak widzi ją Google.
- Crawl Stats - przy większych serwisach pokazuje, czy bot rzeczywiście zagląda tam, gdzie powinien.
- Raport skuteczności - pomaga ocenić, czy rosną wyświetlenia, kliknięcia i CTR.
-
Operator
site:- daje szybki, orientacyjny podgląd, ale nie traktuję go jako źródła prawdy.
W praktyce interesuje mnie nie tylko to, czy strona jest widoczna, ale także kiedy została zaindeksowana i czy liczba zaindeksowanych podstron rośnie razem z publikacją nowych treści. Jeśli indeks jest, a ruchu nadal nie ma, problem jest już bardziej po stronie jakości treści, autorytetu tematu albo samej konkurencyjności zapytania. To prowadzi do ostatniej rzeczy, czyli kolejności działań na nowej stronie.
Co zrobiłbym najpierw na nowej stronie
Gdybym miał uruchomić świeży serwis albo nowy dział w portalu, zacząłbym od kilku prostych ruchów, które ograniczają chaos i dają Google jasny sygnał, co jest ważne. To nie jest efektowna część SEO, ale właśnie ona najczęściej decyduje o tym, czy strona ruszy, czy ugrzęźnie na etapie niewidoczności.
- Sprawdziłbym, czy najważniejsze podstrony nie mają `noindex` i czy są ujęte w sitemapie.
- Połączyłbym nowy materiał z 2-3 mocnymi, już zaindeksowanymi artykułami.
- Upewniłbym się, że treść jest kompletna, a nie tylko „na start” i do późniejszego uzupełnienia.
- Zgłosiłbym kluczowy URL w Search Console i odczekał kilka dni, zamiast klikać wszystko nerwowo co godzinę.
- Po publikacji patrzyłbym na indeksację, wyświetlenia i CTR, a nie tylko na sam fakt opublikowania tekstu.
SEO nie wygrywa się sztuczkami, tylko porządną podstawą: treścią, którą da się znaleźć, zrozumieć i sensownie połączyć z resztą serwisu. Jeśli najpierw uporządkujesz indeksację, a dopiero potem dopracujesz treść i linkowanie, szybciej zobaczysz, co naprawdę działa.