Plik robots.txt jest prostym, ale ważnym elementem technicznego SEO. To on mówi robotom wyszukiwarek, które adresy mogą odwiedzać, a które lepiej zostawić w spokoju, co ma znaczenie dla crawl budgetu, wydajności serwera i porządku w indeksacji. W praktyce największy błąd polega na traktowaniu go jak narzędzia do ukrywania treści, choć jego rola jest dużo bardziej precyzyjna. W tym tekście pokazuję, jak działa, kiedy pomaga, kiedy szkodzi i jak go ustawić bez typowych potknięć.
Najważniejsze rzeczy, które warto wiedzieć o robots.txt
- robots.txt steruje crawlingiem, ale nie gwarantuje usunięcia strony z wyników wyszukiwania.
- Plik musi leżeć w katalogu głównym hosta i być zapisany w UTF-8.
- Najczęściej blokuje się sekcje techniczne, panele administracyjne, koszyk, logowanie i strony testowe.
- Nie warto blokować CSS, JavaScript ani innych zasobów potrzebnych do renderowania strony.
- Błędy w regułach mogą odciąć ważne podstrony od robotów albo zostawić otwartą treść, której nie chcesz indeksować.
- Po wdrożeniu trzeba plik przetestować, bo wyszukiwarki mogą trzymać jego cache nawet przez kilkanaście godzin.
Czym jest robots.txt i czego nie robi
Najprościej mówiąc, robots.txt to instrukcja dla robotów, a nie zamek na drzwi. Według Google Search Central plik służy przede wszystkim do zarządzania dostępem crawlerów do wybranych sekcji serwisu, ale nie jest mechanizmem ukrywania strony przed wyszukiwarką. To ważne rozróżnienie, bo wiele problemów z indeksacją zaczyna się właśnie wtedy, gdy ktoś oczekuje od tego pliku efektu, którego on po prostu nie daje.
Ja traktuję robots.txt jako filtr ruchu. Ma ograniczać zbędne wejścia na podstrony techniczne, powtarzalne lub mało wartościowe, ale nie powinien zastępować blokady indeksowania tam, gdzie treść ma zniknąć z wyników. Jeśli adres jest publicznie dostępny i ktoś go zlinkuje z zewnątrz, sam zakaz crawl często nie wystarczy, aby zniknął z SERP-ów.
| Metoda | Co robi | Kiedy użyć | Ograniczenie |
|---|---|---|---|
| robots.txt | Blokuje lub dopuszcza crawl wybranych ścieżek | Gdy chcesz oszczędzić budżet crawlowania albo odciąć sekcje techniczne | Nie usuwa pewnie adresu z indeksu |
| noindex | Sygnalizuje, że strona nie ma trafiać do indeksu | Gdy robot ma zobaczyć treść, ale nie powinien jej pokazywać w wynikach | Strona musi zostać najpierw pobrana |
| Hasło lub autoryzacja | Faktycznie ogranicza dostęp do treści | Gdy zawartość ma być prywatna | To najmocniejsze zabezpieczenie, ale wymaga dodatkowego logowania |
W praktyce właśnie to porównanie pomaga uniknąć złych decyzji. Jeśli celem jest porządek w crawl budgetcie, robots.txt ma sens. Jeśli celem jest usunięcie konkretnej strony z indeksu, potrzebujesz innego narzędzia. Z tego miejsca przechodzę do reguł, które wyszukiwarki faktycznie rozumieją.
Jak wyszukiwarki czytają reguły
Robot zaczyna od pliku umieszczonego w katalogu głównym danego hosta i czyta reguły przypisane do konkretnego user-agenta. To oznacza, że wersja z www, bez www, na http i na https może mieć osobny plik i osobne zasady. Jeśli prowadzisz większy serwis, ten szczegół ma duże znaczenie, bo jeden błąd w niewłaściwym wariancie domeny potrafi zamknąć indeksację tam, gdzie jej nie planowałeś.
Najważniejsze dyrektywy
| Dyrektywa | Znaczenie | Praktyczna uwaga |
|---|---|---|
| User-agent | Określa, do którego robota odnoszą się kolejne reguły | Możesz kierować osobne zasady do różnych crawlerów |
| Disallow | Zakazuje crawlowania wskazanej ścieżki | Najczęściej używana reguła przy sekcjach technicznych |
| Allow | Dopuszcza crawlowanie wskazanej ścieżki | Pomaga wyjąć z blokady pojedyncze zasoby lub katalogi |
| Sitemap | Wskazuje mapę witryny | Obsługiwana przez najważniejsze wyszukiwarki, ale nie zastępuje dobrej architektury serwisu |
Google nie opiera się na wszystkich możliwych rozszerzeniach, więc nie zakładałbym, że każdy wpis z generatora będzie przez niego respektowany. Na przykład crawl-delay nie jest wspierany przez Google, więc jeśli ktoś korzysta z gotowego szablonu dla innych botów, warto sprawdzić, co faktycznie robią konkretne wyszukiwarki. Dodatkowo w regułach działają proste wildcardy, czyli * oraz $, ale ich użycie trzeba testować, bo zbyt szeroki wzorzec może zablokować więcej, niż planowałeś.
Przeczytaj również: Google Search Console - Jak poprawić SEO? Pełny przewodnik
Ograniczenia, o których łatwo zapomnieć
- Plik musi być zapisany jako UTF-8, inaczej część znaków może zostać zignorowana.
- Google stosuje limit rozmiaru pliku na poziomie 500 KiB, a to, co poza limitem, nie jest brane pod uwagę.
- Wyszukiwarki cache’ują robots.txt, więc nowa wersja nie zawsze działa natychmiast.
- Reguły dotyczą hosta, protokołu i portu, więc nie zakładaj, że jedna wersja obejmie wszystko.
To właśnie te detale rozróżniają poprawny plik od takiego, który tylko wygląda poprawnie. Kiedy już wiesz, jak robot odczytuje zasady, można przejść do praktyki i ustawić je tak, żeby wspierały widoczność zamiast ją tłumić.
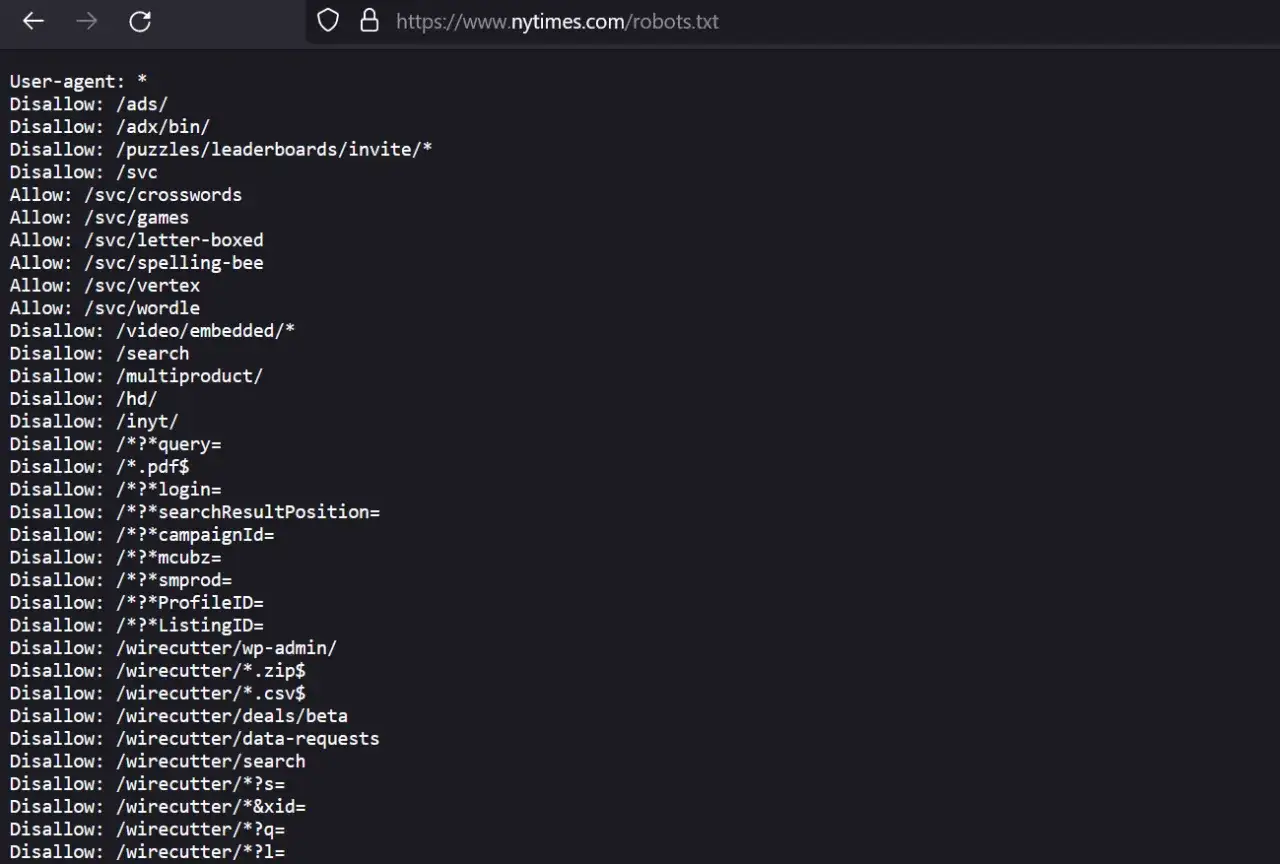
Jak przygotować plik robots.txt, który pomaga zamiast przeszkadzać
Jeżeli mam przygotować sensowny plik dla serwisu, zaczynam od listy sekcji, które generują szum, a nie ruch: panel administracyjny, koszyk, logowanie, wewnętrzna wyszukiwarka, filtry z parametrami i środowiska testowe. Dopiero potem zostawiam to, co ma realną wartość dla użytkownika i wyszukiwarki. Taki porządek zwykle daje lepszy efekt niż szerokie blokowanie całych katalogów bez planu.
User-agent: *
Disallow: /admin/
Disallow: /koszyk/
Disallow: /konto/
Disallow: /szukanie/
Allow: /assets/
Allow: /images/Ten układ jest prosty, ale w wielu wdrożeniach wystarcza jako punkt wyjścia. Blokujesz obszary techniczne, a jednocześnie zostawiasz robotom dostęp do zasobów potrzebnych do poprawnego wyrenderowania strony. To ważne, bo jeśli odetniesz CSS albo JavaScript, wyszukiwarka może zobaczyć stronę w zubożonej wersji i błędnie ocenić jej jakość.
W serwisach e-commerce i dużych blogach dobre wyniki daje też świadome obchodzenie się z parametrami URL. Jeśli filtr kolorów, sortowania albo rozmiaru tworzy tysiące podobnych adresów, lepiej ograniczyć ich crawl niż pozwolić robotowi kręcić się w pętli. Nie chodzi jednak o automatyczne blokowanie wszystkiego, co ma znak zapytania w adresie, tylko o odcięcie naprawdę zbędnych wariantów.
W praktyce ta sekcja często wywołuje najwięcej pytań, bo łatwo pomylić porządkowanie crawl budgetu z próbą naprawy duplikacji treści. A to prowadzi do błędów, które potrafią kosztować widoczność.
Najczęstsze błędy, które psują indeksację
Najwięcej szkód robią pozornie drobne pomyłki. Najgorsza jest oczywiście blokada całej witryny, ale równie częste są przypadki, w których ktoś odcina zasoby potrzebne do renderowania albo próbuje użyć robots.txt do usunięcia strony z indeksu. To właśnie tutaj widać różnicę między „mam plik” a „mam dobrze ustawiony plik”.
| Błąd | Skutek | Lepsze podejście |
|---|---|---|
| Disallow dla całej domeny | Roboty przestają sensownie crawlowć serwis | Blokuj tylko wskazane katalogi, nigdy całej strony bez powodu |
| Blokowanie CSS i JS | Gorsze renderowanie i błędna ocena strony | Zostaw zasoby techniczne dostępne dla crawlerów |
| Użycie robots.txt do ukrywania treści | Adres może nadal pojawić się w wynikach | Jeśli chcesz wyłączyć indeksację, użyj noindex lub zabezpieczenia |
| Zły wariant hosta albo protokołu | Reguły nie działają tam, gdzie powinny | Sprawdź osobno wersję z www, bez www, http i https |
| Za duży lub źle zakodowany plik | Część instrukcji może zostać zignorowana | Trzymaj plik w UTF-8 i pilnuj jego rozmiaru |
Jest jeszcze jedna pułapka, którą widzę często przy audytach. Jeśli strona ma być nieindeksowana, ale nadal potrzebujesz, by robot ją odwiedził i odczytał sygnały takie jak canonical albo noindex, nie blokuj jej w robots.txt. Gdy zablokujesz crawl, wyszukiwarka nie zobaczy tych wskazówek. Zamiast więc walczyć z objawem, trzeba dobrać właściwy mechanizm do celu.
Kiedy blokować, a kiedy zostawić robotom wolną rękę
Nie każda podstrona zasługuje na to samo traktowanie. Ja patrzę na to w prosty sposób: jeśli adres ma wartość dla użytkownika i może zdobywać ruch, powinien być dostępny. Jeśli generuje tylko techniczny hałas, budżet crawlowania lepiej przeznaczyć gdzie indziej. To podejście działa szczególnie dobrze w dużych serwisach, gdzie liczba adresów rośnie szybciej niż realna wartość contentu.
| Sytuacja | Co zwykle robię | Dlaczego |
|---|---|---|
| Panel administracyjny | Blokuję crawl | To obszar techniczny, bez wartości dla indeksu |
| Koszyk i finalizacja zakupu | Blokuję crawl | Te adresy nie powinny walczyć o widoczność |
| Wewnętrzna wyszukiwarka | Najczęściej blokuję | Może tworzyć nieskończoną liczbę słabo wartościowych URL-i |
| Filtry i sortowanie | Decyduję indywidualnie | Niektóre parametry są bezpieczne, inne generują duplikaty |
| CSS, JS, obrazy | Zostawiam dostępne | Robot musi je zobaczyć, żeby poprawnie wyrenderować stronę |
| Strona, która ma zniknąć z wyników | Nie opieram się na robots.txt | Lepszy jest noindex albo blokada dostępu |
Tu właśnie widać, że robots.txt nie jest uniwersalnym wyłącznikiem. Gdy blokujesz zbyt dużo, możesz odciąć wyszukiwarkę od treści, która naprawdę powinna rankować. Gdy blokujesz za mało, robot marnuje czas na adresy techniczne i niepotrzebne warianty. Dobrze ustawiony plik siedzi dokładnie pomiędzy tymi skrajnościami.
Co sprawdzić po wdrożeniu, żeby nie zgasić ruchu organicznego
Po każdej zmianie robię szybki audyt kontrolny, bo właśnie wtedy wychodzą błędy, których nie widać na pierwszy rzut oka. Najpierw sprawdzam, czy plik jest publicznie dostępny i czy zwraca poprawny status. Potem patrzę na ważne adresy, żeby upewnić się, że nie zostały przypadkiem objęte regułą blokującą.
- Otwórz plik w przeglądarce prywatnej i sprawdź, czy da się go pobrać bez logowania.
- Zweryfikuj, czy kluczowe sekcje serwisu nie są objęte przypadkowym disallow.
- Sprawdź raport robots.txt w Google Search Console, jeśli korzystasz z Google.
- Przetestuj najważniejsze adresy także w Bing Webmaster Tools, jeśli ruch z Bing ma dla Ciebie znaczenie.
- Przejrzyj logi serwera, żeby zobaczyć, czy roboty rzeczywiście omijają tylko to, co miały ominąć.
- Monitoruj indeksację przez kilka dni, bo cache pliku może opóźnić efekt zmian.
Ja po zmianach zawsze zakładam, że pełny efekt nie musi pojawić się natychmiast. W praktyce roboty mogą korzystać z cache poprzedniej wersji nawet przez pewien czas, więc brak szybkiej reakcji nie zawsze oznacza błąd. Jeśli jednak po wdrożeniu spada widoczność albo znikają ważne URL-e, pierwsze co sprawdzam, to właśnie robots.txt, a zaraz potem canonicale i noindex. To zwykle najszybciej prowadzi do źródła problemu i pozwala wrócić do stabilnej indeksacji bez zgadywania.