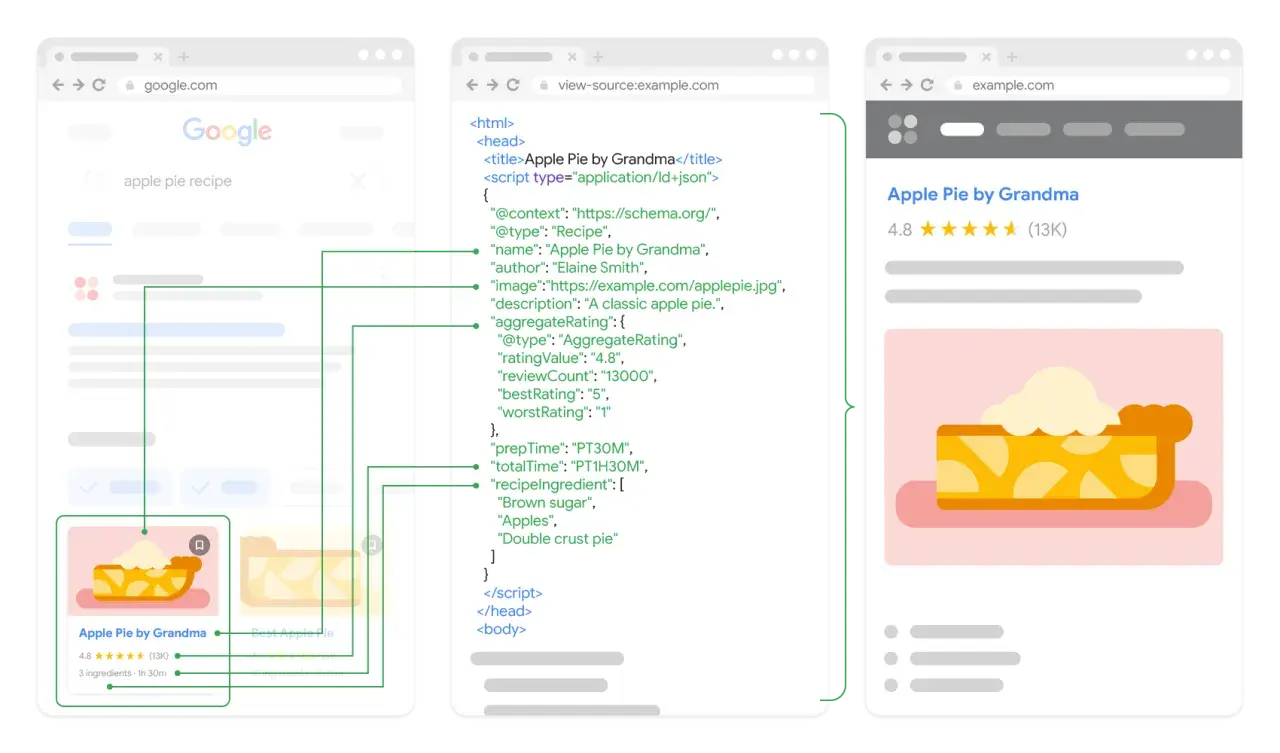
Dobrze ustawione dane uporządkowane pomagają wyszukiwarce szybciej zrozumieć, co naprawdę znajduje się na stronie, i zwiększają szansę na bogatszy wynik w wynikach wyszukiwania. W praktyce schema google najczęściej przydaje się wtedy, gdy chcesz uporządkować artykuły, produkty, breadcrumbs albo informacje o firmie, zamiast liczyć na przypadkowy efekt. Najwięcej daje tam, gdzie treść jest precyzyjna, powtarzalna i spójna z tym, co użytkownik widzi na stronie.
Najważniejsze informacje na start
- Dane uporządkowane pomagają wyszukiwarce lepiej rozumieć treść, ale nie zastępują indeksacji.
- Najbezpieczniejszym formatem wdrożenia jest zwykle JSON-LD.
- Najczęściej zaczynam od Article, BreadcrumbList, Organization i Product.
- Schema nie naprawia problemów z noindex, robots.txt ani kanonicznością.
- Po wdrożeniu sprawdzam Rich Results Test, URL Inspection i Search Console.
Czym są dane uporządkowane i dlaczego pomagają wyszukiwarce
To nie jest dekoracja kodu, tylko warstwa opisowa, która mówi robotowi: to jest autor, to jest cena, to jest data publikacji, a to są okruszki nawigacyjne. Dzięki temu wyszukiwarka łatwiej buduje kontekst, a czasem pokazuje rich result, czyli wynik z dodatkowymi elementami, które wyróżniają stronę na tle zwykłych linków.
Ja patrzę na to prosto: jeśli strona mówi o konkretnym obiekcie albo usłudze, schema pomaga nazwać tę rzecz w sposób czytelny dla maszyny. Encja, czyli rozpoznawalny przez system obiekt, staje się dzięki temu mniej „domyślna”, a bardziej jednoznaczna. To szczególnie ważne w serwisach contentowych, technicznych i e-commerce, gdzie struktura treści powtarza się na wielu podstronach.
Najlepiej działa to wtedy, gdy dane są stabilne i dobrze zmapowane do szablonu. Dopiero na takim gruncie ma sens pytanie, co schema daje w SEO, a czego nie załatwia samym znacznikiem.
Co schema daje w SEO, a czego nie załatwia
Największy błąd, jaki widzę, to traktowanie danych uporządkowanych jak skrótu do pozycji. To nie tak działa. Schema może pomóc wyszukiwarce zrozumieć stronę i zwiększyć szansę na lepszą prezentację wyniku, ale nie jest magicznym przyciskiem od ruchu organicznego.
| Co faktycznie daje | Czego nie daje |
|---|---|
| Lepszy kontekst dla treści i typu strony, większą szansę na bogatszy wynik, spójniejsze dane w szablonie | Gwarancji indeksacji, wyższej pozycji, obejścia noindex ani naprawy słabej treści |
To rozróżnienie ma znaczenie praktyczne. Jeśli strona jest zablokowana przez noindex, robots.txt albo błędną kanoniczność, czyli wskazanie innej wersji jako głównej, wyszukiwarka może w ogóle nie dojść do etapu użycia danych strukturalnych. Sam markup nie przykryje problemów technicznych, a czasem tylko daje złudne poczucie, że „coś już jest zrobione”.
Warto też pamiętać, że wynik rozszerzony nie jest czymś, co dostaje się automatycznie po poprawnym wdrożeniu. Właśnie dlatego sensowne jest pytanie o typ danych, format i miejsce wdrożenia, a nie o sam efekt wizualny. I tu przechodzę do najpraktyczniejszej części.
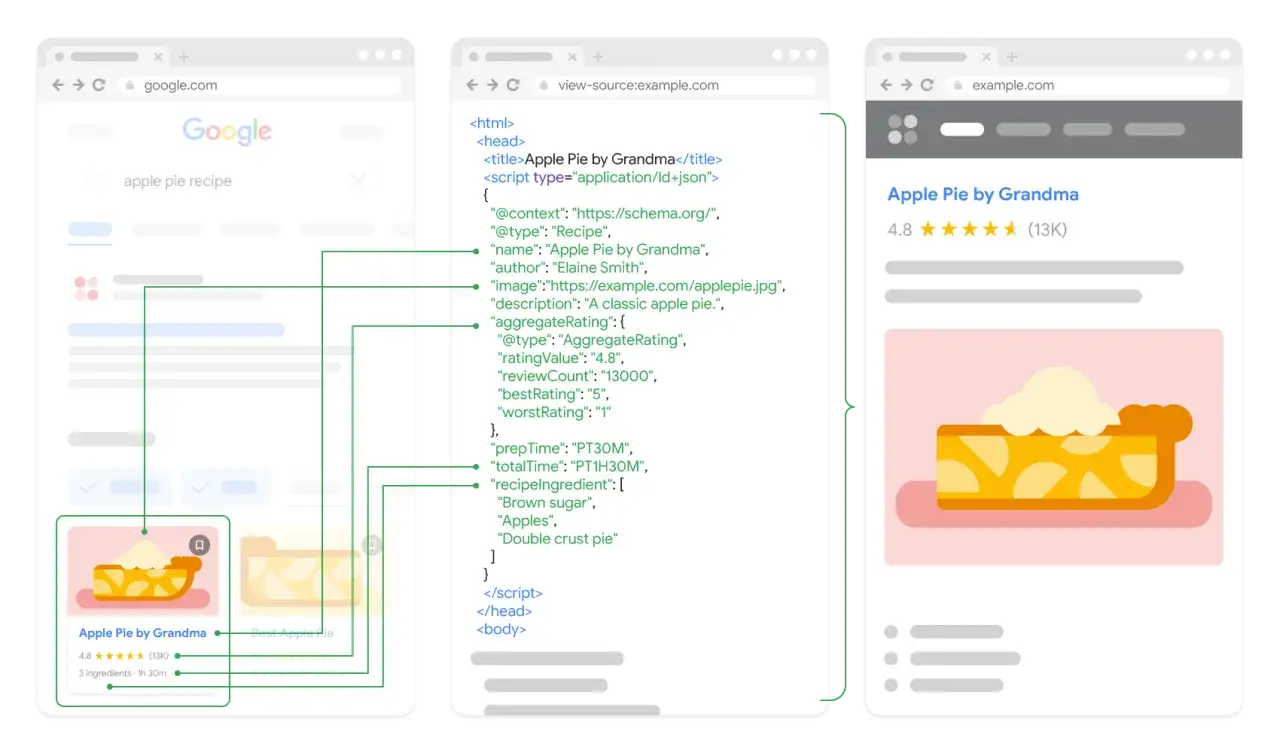
Jakie typy danych wdrażać najpierw
Na portalu technologicznym, blogu firmowym albo serwisie z ofertą nie wdrażałbym wszystkiego naraz. Zaczynam od tych typów, które najczęściej niosą realną wartość i łatwo sprawdzić ich poprawność.
| Typ strony | Najczęściej użyteczne oznaczenie | Po co je wdrażać |
|---|---|---|
| Artykuł, poradnik, analiza | Article | Porządkuje tytuł, autora, datę publikacji i obraz strony. |
| Nawigacja i kategorie | BreadcrumbList | Pomaga odczytać hierarchię serwisu i kontekst podstrony. |
| Strona firmy lub marki | Organization | Łączy nazwę, logo i podstawowe informacje o podmiocie. |
| Strona produktu lub oferty | Product | Daje jasny sygnał o cenie, dostępności i wariancie. |
| Strona aplikacji lub narzędzia | SoftwareApplication | Porządkuje opis produktu cyfrowego i jego funkcje. |
Jeśli chodzi o sam format kodu, najczęściej wybieram JSON-LD. Jest najmniej inwazyjny, najłatwiejszy w utrzymaniu i najlepiej pasuje do wdrożeń na szablonie, a nie do ręcznego doklejania atrybutów w HTML. Microdata i RDFa też istnieją, ale w większości współczesnych projektów traktuję je raczej jako rozwiązania drugiego wyboru, zwykle przy starszych systemach albo ograniczeniach po stronie CMS.
Gdy typ danych jest już wybrany, sensownie przejść do wdrożenia krok po kroku, bo to właśnie na etapie implementacji najłatwiej o drobne błędy, które później psują cały efekt.
Jak wdrożyć to bez chaosu
Ja zwykle zaczynam od jednej strony wzorcowej, a nie od całego serwisu. To pozwala sprawdzić, czy szablon, dane z CMS-a i widoczna treść naprawdę mówią to samo.
Zacznij od strony o największym potencjale
Najpierw wybieram podstronę, która ma sens biznesowy i jest technicznie reprezentatywna. Jeśli wdrożenie działa na jednym szablonie, łatwiej potem rozszerzyć je na resztę serwisu bez ręcznego poprawiania każdej podstrony osobno.
Oznacz tylko to, co użytkownik widzi
To jedna z zasad, której nie lekceważę. Jeśli kod mówi o cenie, autorze, produkcie albo dacie, te informacje muszą być widoczne na stronie i zgodne z treścią. Ukrywanie danych w schema, których nie ma w HTML-u, zwykle kończy się problemem zamiast korzyści.
Wdróż na poziomie szablonu, nie pojedynczego wpisu
W poprawnym wdrożeniu ważna jest powtarzalność. Gdy wartości pochodzą z CMS-a, odświeżają się razem z treścią i nie rozjeżdżają się po kilku tygodniach. To szczególnie istotne przy datach, cenach, dostępności i autorach, bo właśnie tam ręczne poprawki psują się najszybciej.
Przeczytaj również: Wiek domeny a SEO - Czy starsza strona faktycznie pomaga?
Sprawdź, czy robot ma do strony dostęp
Jeżeli strona jest blokowana przez robots.txt, noindex albo wymaga logowania, to nawet idealny markup niewiele da. Widoczność strony dla robota jest warunkiem wstępnym, a nie dodatkiem. Schema ma wspierać indeksację i interpretację, nie zastępować podstaw technicznych.
Po wdrożeniu przechodzę od kodu do testów, bo dopiero one pokazują, czy wszystko złożyło się w sensowną całość.
Najczęstsze błędy, które psują efekt
W praktyce problemy z danymi uporządkowanymi rzadko wynikają z „braku SEO”, a częściej z niedbałej implementacji. To są błędy, które widzę najczęściej:
- Oznaczanie treści, której użytkownik nie widzi na stronie.
- Rozjazd między schema a widocznymi danymi, na przykład inną datą, ceną albo autorem.
- Wdrażanie danych na stronie z noindex, błędnym canonicalem lub blokadą w robots.txt.
- Kopiowanie jednego schematu na wiele typów podstron bez sprawdzenia, czy pasuje do treści.
- Przeciążanie strony wieloma typami danych bez potrzeby i bez kontroli spójności.
- Stawianie wszystkiego na FAQPage, mimo że ten format ma dziś mocno ograniczoną widoczność dla większości serwisów.
Ostatni punkt jest ważny, bo stare poradniki często wciąż sugerują, że FAQ schema to uniwersalny skrót do lepszego snippetu. W praktyce to już nie jest strategia, na której budowałbym całą widoczność. Jeśli coś przestaje być wspierane szeroko, trzeba to po prostu traktować jako dodatkowy, a nie główny element wdrożenia.
Gdy te błędy są wyeliminowane, można przejść do kontroli jakości i sprawdzenia, czy wyszukiwarka naprawdę rozumie to tak samo jak my.
Jak sprawdzać, czy wdrożenie działa
Samego kodu nie oceniam na oko. Najpierw patrzę, czy narzędzia pokazują poprawność składni, a dopiero potem sprawdzam, czy strona jest indeksowana i czy oznaczenia mają szansę zostać użyte w wynikach.
| Narzędzie | Do czego go używam |
|---|---|
| Rich Results Test | Do sprawdzenia, czy markup jest poprawny i czy strona kwalifikuje się do wybranych wyników rozszerzonych. |
| URL Inspection | Do sprawdzenia, jak robot widzi stronę na żywo i czy jest faktycznie indeksowana. |
| Search Console | Do monitorowania statusu danych, błędów i zmian po wdrożeniu nowych szablonów. |
| Manual Actions | Do wykrycia sytuacji, w której schema została uznana za naruszającą wytyczne. |
Ja zwracam uwagę nie tylko na poprawność syntaktyczną, ale też na to, czy strona została już zindeksowana i czy nie ma rozjazdu między wersją kanoniczną a tą, na której leży markup. Jeśli dane są na duplikacie, a nie na stronie kanonicznej, efekt zwykle znika albo nigdy się nie pojawia.
Na koniec patrzę na dane z perspektywy czasu, a nie jednego dnia. CTR, liczba kliknięć i widoczność bogatszych wyników mają sens dopiero wtedy, gdy porównujesz je z wcześniejszym okresem i z podobnymi stronami bez takiego oznaczenia.
Co zostaje, nawet gdy wynik rozszerzony się nie pokazuje
To, co najcenniejsze w dobrze wdrożonym schemacie, nie zawsze widać od razu w SERP-ie. Nawet jeśli bogatszy wynik się nie pojawi, strona zyskuje lepszy porządek danych, łatwiejsze zarządzanie treścią i większą spójność między CMS-em a HTML-em.
- Masz bardziej czytelny model danych dla zespołu SEO i programistów.
- Łatwiej utrzymać aktualność dat, cen, autorów i breadcrumbs.
- Zmniejszasz ryzyko błędów przy migracji, zmianie szablonu lub przebudowie serwisu.
- Dajesz wyszukiwarce dodatkowy kontekst, nawet jeśli nie obiecuje on konkretnego wyglądu wyniku.
Jeśli miałbym zostawić jedną zasadę, to taką: schema ma opisywać stronę, a nie zastępować dobrą stronę. Gdy treść, indeksacja i kanoniczność są uporządkowane, dane strukturalne przestają być ozdobą, a stają się realnym wsparciem SEO.