
Najkrótsza odpowiedź brzmi tak
- Uczenie maszynowe to część AI, w której model uczy się na danych zamiast dostawać wszystkie reguły ręcznie.
- Najpierw zbiera się dane, potem trenuje model, sprawdza go na osobnym zbiorze i dopiero wdraża do użycia.
- Najczęściej spotyka się uczenie nadzorowane, nienadzorowane, ze wzmocnieniem oraz samonadzorowane.
- Dobre dane są zwykle ważniejsze niż sam algorytm, bo model nie poprawi jakości informacji, których nie dostał.
- ML napędza rekomendacje, wykrywanie nadużyć, rozpoznawanie obrazu, prognozowanie i wiele narzędzi generatywnych.
- Największe ryzyko to nie „zły model”, tylko złe założenia, słaba walidacja i brak monitoringu po wdrożeniu.
Na czym polega uczenie maszynowe
Ja najczęściej tłumaczę to tak: zamiast ręcznie opisywać komputerowi każdą regułę, pokazujesz mu przykłady i pozwalasz samodzielnie znaleźć zależności. Efektem nie jest „inteligencja” w ludzkim sensie, tylko model, czyli matematyczny zapis tego, czego system nauczył się z danych. Taki model może potem przewidywać wynik dla nowych danych, np. odfiltrowywać spam, rozpoznawać obiekty na zdjęciach albo podpowiadać produkt, który użytkownik najpewniej wybierze.
To właśnie dlatego uczenie maszynowe jest tak praktyczne: dobrze działa tam, gdzie reguły są zbyt złożone, zbyt liczne albo ciągle się zmieniają. W klasycznym programowaniu programista zapisuje zasady wprost, a tutaj to dane „uczą” system zachowania. Gdy rozumiesz tę różnicę, dużo łatwiej odróżnić prawdziwy model ML od zwykłej automatyzacji ubranej w modną nazwę.
Warto też odróżnić algorytm od modelu. Algorytm to sposób uczenia, a model to gotowy rezultat treningu, czyli coś, co można już wykorzystać w aplikacji. Żeby zobaczyć, jak ten proces wygląda w praktyce, trzeba przejść od definicji do etapów pracy z danymi.
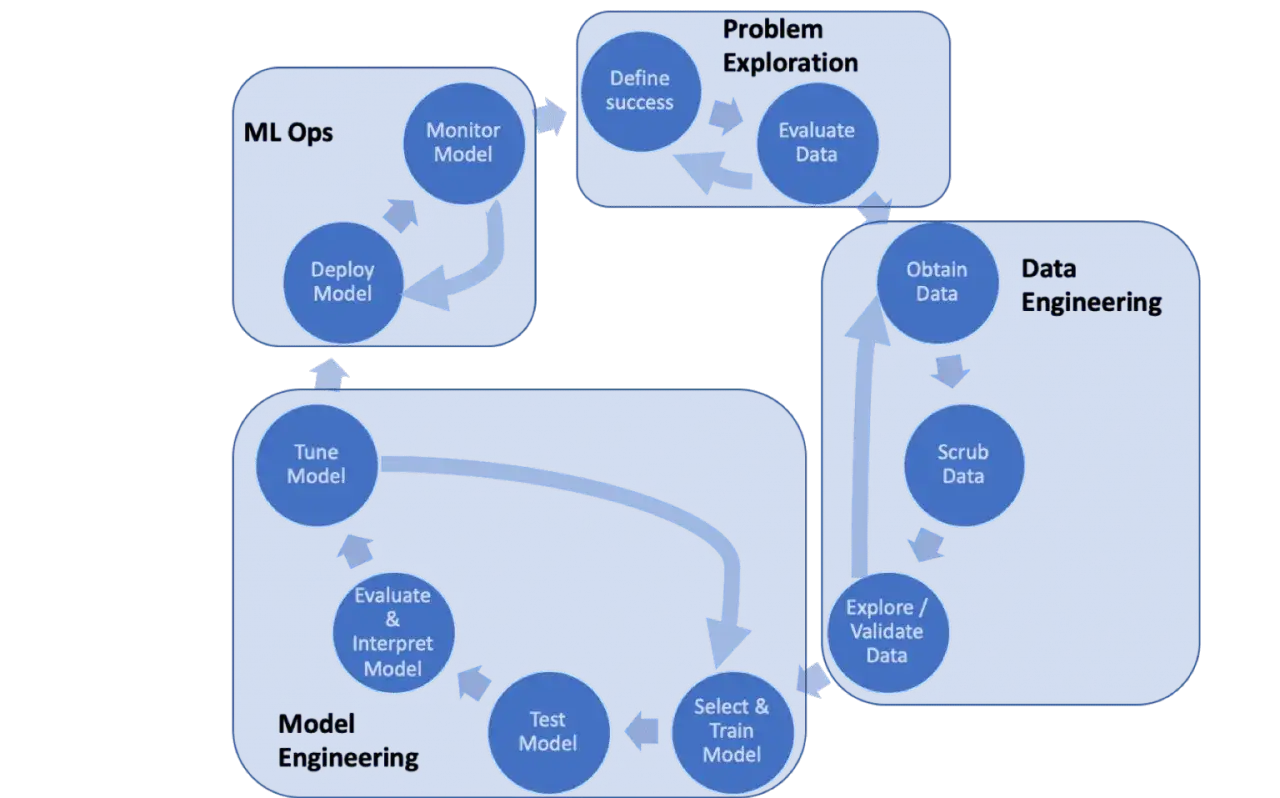
Jak model uczy się na danych
Najpierw potrzebujesz danych, bo bez nich nie ma na czym budować wzorców. Dane zwykle dzieli się na zbiór treningowy, walidacyjny i testowy: pierwszy służy do nauki, drugi do strojenia, trzeci do sprawdzenia, jak model poradzi sobie z nowymi przykładami. Jeśli te role się mieszają, wyniki zaczynają być mylące, a model wygląda lepiej na papierze niż w realnym użyciu.
Dane i cechy
Model nie „widzi” świata tak jak człowiek. Pracuje na cechach, czyli właściwościach opisujących dane wejściowe. W spam filtrze mogą to być słowa i ich częstotliwość, w sklepie internetowym historia kliknięć, a w analizie obrazu położenie i kolor pikseli. Im lepiej dobrane cechy, tym większa szansa, że model znajdzie sensowny wzorzec.
Trenowanie i walidacja
Trening polega na takim dopasowaniu parametrów modelu, aby jak najlepiej odtwarzał zależność między wejściem a wynikiem. Walidacja sprawdza, czy model nie nauczył się tylko pamięci do danych treningowych. Tu często pojawia się overfitting, czyli sytuacja, w której model świetnie radzi sobie z przykładami, które już widział, ale gorzej z nowymi. To jeden z tych błędów, które w statystykach potrafią wyglądać niegroźnie, a w produkcji bolą natychmiast.
Przeczytaj również: GPT-4 - Czym różni się od ChatGPT i jak wycisnąć z niego więcej?
Wdrożenie i monitorowanie
Dobry model nie kończy życia po treningu. Po wdrożeniu trzeba obserwować jego skuteczność, bo dane w czasie się zmieniają. To zjawisko nazywa się data drift, czyli przesunięciem rozkładu danych wejściowych. Jeśli firma zmienia produkt, zachowania użytkowników ewoluują albo rynek reaguje inaczej niż wcześniej, model wymaga ponownego dostrojenia. Bez tego nawet sensowny projekt szybko traci jakość.
Gdy ten proces jest jasny, dużo łatwiej zrozumieć, jakie istnieją odmiany uczenia i czemu nie każdy problem rozwiązuje się tym samym podejściem.
Jakie są główne rodzaje uczenia
Najprościej patrzeć na to przez pryzmat informacji, jaką dostaje model na wejściu. W praktyce to właśnie typ danych decyduje o tym, czy szukasz odpowiedzi znanych wcześniej, czy raczej ukrytych struktur.
| Rodzaj | Na czym polega | Gdzie się sprawdza | Ograniczenie |
|---|---|---|---|
| Uczenie nadzorowane | Model dostaje dane z etykietami, czyli znanymi odpowiedziami | Klasyfikacja, prognozowanie, scoring, wykrywanie spamu | Wymaga dobrych, ręcznie oznaczonych danych |
| Uczenie nienadzorowane | Model szuka wzorców w danych bez gotowych odpowiedzi | Segmentacja klientów, wykrywanie anomalii, grupowanie podobnych przypadków | Trudniej ocenić, czy wynik rzeczywiście ma sens biznesowy |
| Uczenie ze wzmocnieniem | Model uczy się przez nagrody i kary w interakcji ze środowiskiem | Robotyka, gry, sterowanie, optymalizacja decyzji | Wymaga dobrze zdefiniowanego środowiska i cierpliwego treningu |
| Uczenie samonadzorowane | Model tworzy sygnał uczący z samych danych | Duże modele językowe, wizja komputerowa, pretrening nowoczesnych systemów AI | Jest obliczeniowo kosztowne i wymaga dużych zbiorów danych |
W projektach biznesowych najczęściej wygrywa uczenie nadzorowane, bo daje najłatwiej mierzalny efekt. Z kolei uczenie nienadzorowane bywa niedoceniane, choć świetnie nadaje się do odkrywania wzorców, których nikt wcześniej nie zdefiniował. To prowadzi do bardzo praktycznego pytania: gdzie ML faktycznie daje przewagę, a gdzie jest tylko kosztownym dodatkiem?
Gdzie uczenie maszynowe daje realną przewagę
Nie każdy problem warto oddawać modelowi, ale są obszary, w których przewaga jest wyraźna. Tam, gdzie danych jest dużo, a reguły są zbyt skomplikowane do ręcznego opisania, ML zwykle robi różnicę szybciej niż klasyczne podejście.
- Rekomendacje treści i produktów - system analizuje zachowania użytkownika i podpowiada rzeczy, które zwiększają szansę na kliknięcie lub zakup. To nie jest magia, tylko statystyka na dużej skali.
- Wykrywanie nadużyć - modele dobrze wychwytują nietypowe wzorce w płatnościach, logowaniach czy transakcjach, więc są naturalnym wsparciem dla bankowości i e-commerce.
- Rozpoznawanie obrazu i tekstu - od OCR po analizę zdjęć medycznych i filtrowanie treści. Tu ML wygrywa, bo potrafi pracować z chaotycznymi danymi, których ręczne opisywanie byłoby niepraktyczne.
- Prognozowanie popytu - przydaje się w logistyce, handlu i produkcji. Model nie zgaduje przyszłości, ale uczy się sezonowości i zależności, które człowiek łatwo przeocza.
- Asystenci i narzędzia generatywne - współczesne systemy AI do tekstu, obrazu czy kodu też opierają się na modelach uczonych na danych, więc ML siedzi tu pod spodem, nawet jeśli użytkownik widzi tylko gotowy wynik.
Najważniejsze jest jednak to, że przewaga pojawia się dopiero wtedy, gdy problem jest powtarzalny, mierzalny i ma sensowną ilość danych. To naturalnie prowadzi do porównania z AI i deep learningiem, bo te pojęcia bardzo łatwo się ze sobą miesza.
Czym różni się od AI, deep learningu i zwykłego programowania
To miejsce, w którym najczęściej pojawia się chaos pojęciowy. Dla porządku rozdzielam te terminy, bo w praktyce używa się ich zamiennie, choć oznaczają coś innego.
| Pojęcie | Znaczenie | Co warto zapamiętać |
|---|---|---|
| Sztuczna inteligencja | Najszersza kategoria systemów, które wykonują zadania wymagające zwykle „inteligentnego” zachowania | AI to parasol nad wieloma metodami, nie jedna technika |
| Uczenie maszynowe | Jedna z gałęzi AI, w której system uczy się z danych | To praktyczny sposób budowania modeli, które poprawiają działanie na podstawie doświadczenia |
| Deep learning | Specjalny rodzaj ML oparty na wielowarstwowych sieciach neuronowych | Dobrze radzi sobie z obrazem, dźwiękiem i językiem, ale zwykle wymaga więcej danych i mocy obliczeniowej |
| Klasyczne programowanie | Programista zapisuje reguły, a komputer je wykonuje | Dobre tam, gdzie zasady są jasne i stabilne; słabsze tam, gdzie świat jest zbyt zmienny lub złożony |
W skrócie: jeśli reguły da się jasno opisać, klasyczny kod bywa prostszy i tańszy. Jeśli reguł jest zbyt dużo, dane są niejednoznaczne albo środowisko się zmienia, uczenie maszynowe zaczyna mieć sens. Z kolei deep learning jest po prostu bardziej wyspecjalizowanym i zwykle cięższym narzędziem w tej samej rodzinie.
Kiedy te granice są już jasne, łatwiej zobaczyć, dlaczego jedne projekty działają świetnie, a inne rozjeżdżają się mimo dobrego startu.
Najczęstsze błędy, które psują projekt
W praktyce rzadko przegrywa sam algorytm. Znacznie częściej przegrywa założenie, że model „sam się domyśli”, co jest ważne. To podejście kończy się słabą jakością danych, złą metryką albo systemem, którego nikt później nie monitoruje.
- Za mało lub za słabe dane - model nie wyczaruje wiedzy, której nie ma w zbiorze uczącym.
- Przesadny optymizm wobec wyniku - wysoka skuteczność na danych testowych nie zawsze oznacza dobrą pracę po wdrożeniu.
- Brak kontroli biasu - jeśli dane historyczne są stronnicze, model często powiela ten sam problem zamiast go naprawiać. Bias to uprzedzenie ukryte w danych lub procesie ich zbierania.
- Ignorowanie zmian w czasie - model, który działał świetnie rok temu, dziś może wymagać ponownego treningu.
- Dobór złej metryki - skuteczność, precyzja, recall i F1 to nie to samo; każda odpowiada na inne pytanie.
- Zbyt duża wiara w automatyzację - nawet dobry model nie zastępuje sensownego procesu decyzyjnego.
Jeśli miałbym wskazać jedną rzecz, która najczęściej robi największą różnicę, postawiłbym na jakość danych i sensowną ocenę wyniku, a nie na pogoń za najbardziej efektowną techniką. Z takim podejściem dużo łatwiej wejść w ostatni krok, czyli praktyczny start w świecie ML.
Jak zacząć, jeśli chcesz wejść głębiej
Nie zaczynaj od „najlepszego modelu”, tylko od małego, mierzalnego problemu. Ja zwykle polecam taką kolejność:
- Poznaj podstawy Pythona - bez tego trudno pracować wygodnie z danymi i bibliotekami ML.
- Naucz się pracy z danymi - pandas i numpy to minimum, jeśli chcesz czyścić, przekształcać i analizować zbiory danych.
- Zrozum podstawy statystyki - rozkład, korelacja, błąd, wariancja i losowość pomagają unikać prostych pomyłek.
- Przećwicz klasyczne algorytmy - drzewa decyzyjne, regresję liniową, random forest czy k-means pozwalają zbudować intuicję bez wchodzenia od razu w ciężki deep learning.
- Rób małe projekty end to end - od danych przez trening po prosty deployment albo chociaż raport z wynikami. Dopiero wtedy widać, gdzie teoria zderza się z praktyką.
Ta ścieżka jest mniej efektowna niż szybkie skakanie do sieci neuronowych, ale daje lepszą bazę. I właśnie ta baza decyduje później o jakości całego projektu.
Co naprawdę decyduje, czy model będzie użyteczny
Gdybym miał zostawić jedną praktyczną myśl, byłaby prosta: w ML wygrywa nie ten, kto użyje najbardziej modnego narzędzia, tylko ten, kto dobrze definiuje problem i umie ocenić wynik. Model ma sens wtedy, gdy:
- problem jest powtarzalny i da się go mierzyć,
- dane są reprezentatywne dla rzeczywistości,
- metryka odpowiada na prawdziwy cel biznesowy lub produktowy,
- system jest monitorowany po wdrożeniu, a nie zostawiony sam sobie.
Jeśli te warunki są spełnione, uczenie maszynowe przestaje być hasłem z prezentacji, a staje się narzędziem, które realnie poprawia produkt, proces albo decyzję. Jeśli nie są spełnione, nawet najlepszy model będzie tylko kosztowną ciekawostką.