W praktyce termin trust rank odnosi się do sposobu oceny, czy strona wygląda na wiarygodną, czy raczej na witrynę zbudowaną pod manipulację wynikami. Dla SEO i indeksacji ważne są nie tylko linki, ale też to, czy robot potrafi stronę odczytać, zrozumieć jej kanoniczną wersję i uznać content za wart zapisania w indeksie. W tym tekście rozkładam temat na konkretne elementy: czym jest TrustRank, jak łączy się z crawlsem i indeksacją oraz co realnie poprawia widoczność strony.
Najważniejsze wnioski o zaufaniu i indeksacji
- TrustRank wyrósł z akademickiego modelu propagacji zaufania przez linki, ale w praktyce SEO nie działa jak publiczny licznik w panelu.
- Indeksacja zaczyna się od podstaw technicznych: dostępności, statusu 200, poprawnego renderowania i braku blokad w robots.txt.
- noindex wycina stronę z indeksu, a robots.txt blokuje crawl, więc to dwa różne mechanizmy o innym skutku.
- Duplikaty, błędna kanonikalizacja i content dostępny tylko po interakcji użytkownika często szkodzą bardziej niż sam brak linków.
- Największą różnicę robi porządek w URL-ach, spójne linkowanie wewnętrzne, aktualna mapa witryny i treści, które faktycznie zasługują na indeks.
Co naprawdę oznacza TrustRank w SEO
Ja traktuję ten temat dość pragmatycznie: TrustRank nie jest magicznym wskaźnikiem, tylko skrótem myślowym opisującym ocenę zaufania opartego na strukturze linków i jakości źródeł. W klasycznym ujęciu chodzi o to, że zaufanie startuje z ręcznie wybranych, wiarygodnych stron-seedów i rozchodzi się po grafie linków, a im dalej od tych punktów startowych, tym ostrożniej należy oceniać witrynę.
To ważne rozróżnienie, bo w SEO często miesza się trzy różne rzeczy: wiarygodność domeny, zdolność do indeksacji i pozycję w rankingu. To są powiązane obszary, ale nie to samo. Strona może być technicznie dostępna, a mimo to nie trafić do indeksu. Może też być zindeksowana, ale nie wzbudzać zaufania na tyle, by wygrywać z mocniejszą konkurencją.
W praktyce nie patrzę więc na TrustRank jak na metrykę do odczytania z narzędzia. Patrzę na niego jak na opis sytuacji, w której wyszukiwarka pyta: czy tej witrynie warto poświęcić uwagę, crawl i miejsce w indeksie? To prowadzi już prosto do samej indeksacji.
Skoro wiemy, czym jest ten mechanizm w teorii, czas przejść do tego, jak roboty wyszukiwarek faktycznie widzą stronę i gdzie zaufanie zaczyna mieć znaczenie operacyjne.

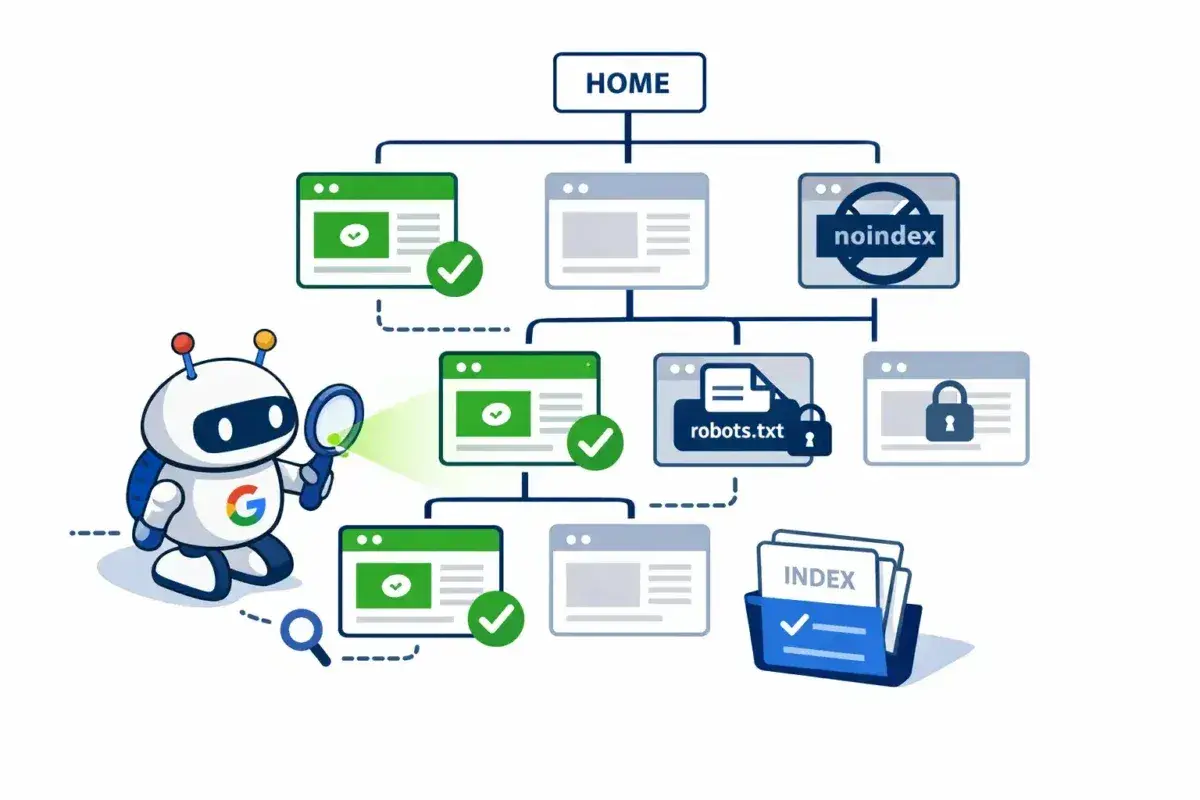
Jak indeksacja łączy się z oceną zaufania
Indeksacja nie zaczyna się od „czy treść jest dobra”, tylko od prostszego pytania: czy robot w ogóle może stronę pobrać, wyrenderować i zrozumieć? Według dokumentacji Google Search Central proces wygląda warstwowo: najpierw crawl, potem renderowanie, potem ocena, czy dana wersja URL-a ma trafić do indeksu. I co ważne, samo zeskanowanie strony nie oznacza jeszcze, że zostanie ona zindeksowana.| Etap | Co się dzieje | Co ma znaczenie praktyczne |
|---|---|---|
| Crawl | Robot pobiera URL i sprawdza odpowiedź serwera. | Liczą się dostępność, status 200, brak blokad i sensowna szybkość odpowiedzi. |
| Render | Wyszukiwarka odtwarza stronę, w tym JavaScript. | Treść powinna być widoczna bez klikania, przewijania i zgadywania, co się pojawi później. |
| Index | System wybiera wersję kanoniczną i decyduje, czy zapisze ją w indeksie. | Tu wchodzą w grę canonicale, duplikaty, noindex i jakość samej strony. |
Ja zwykle tłumaczę to tak: crawl to wejście do budynku, render to odczytanie tabliczek na drzwiach, a indeksacja to decyzja, czy ten adres w ogóle warto dopisać do książki. Jeśli coś blokuje którykolwiek z tych kroków, „zaufanie” przestaje być abstrakcją, a staje się realnym problemem technicznym.
Ważne jest też to, że Google nie indeksuje wszystkiego, co odwiedzi. Może pobrać stronę, ale uznać ją za niekanoniczną, zduplikowaną, słabą jakościowo albo niewystarczająco użyteczną. W praktyce oznacza to, że dobra strategia SEO musi działać jednocześnie na poziomie technicznym i redakcyjnym.
To prowadzi do pytania, jakie sygnały naprawdę wzmacniają wiarygodność witryny, zamiast tylko ładnie wyglądać w audycie.
Jakie sygnały realnie budują wiarygodność strony
Jeśli miałbym wskazać najważniejszą rzecz, powiedziałbym: spójność. Dla wyszukiwarki wiarygodna strona to nie taka, która ma najwięcej ozdobników, tylko taka, która konsekwentnie pokazuje ten sam temat, ten sam adres kanoniczny i ten sam standard jakości.
- Spójność tematyczna - serwis powinien konsekwentnie rozwijać jeden obszar, zamiast skakać między przypadkowymi tematami bez logicznego rdzenia.
- Autorytet tematyczny - to po prostu głębokość pokrycia tematu, a nie liczba wpisów na ślepo. Jeden dobry filar bywa wart więcej niż dziesięć powierzchownych notek.
- E-E-A-T - skrót od doświadczenia, ekspertyzy, autorytetu i wiarygodności; w praktyce oznacza to jasne autorstwo, źródła, dane o firmie i brak anonimowości tam, gdzie użytkownik oczekuje odpowiedzialności.
- Porządek w linkowaniu - wewnętrzne linki powinny prowadzić do kanonicznych wersji stron i wzmacniać najważniejsze treści, a nie rozpraszać sygnały na duplikaty.
- Jasne sygnały redakcyjne - daty, autor, aktualizacja, polityka treści i sensowne nagłówki pomagają ocenić, czy materiał jest żywy i utrzymywany.
- Naturalny profil linków - linki z tematów bliskich branży są cenniejsze niż przypadkowe wzmianki z miejsc, które nie mają żadnego związku z tematyką.
W praktyce nie ma sensu próbować „nabijać zaufania” samym wiekiem domeny albo samymi backlinkami z katalogów. To działa coraz słabiej, bo systemy oceny jakości są projektowane po to, by widzieć kontekst, a nie tylko liczbę odnośników.
W serwisach technologicznych, programistycznych i AI widać to szczególnie mocno: wygrywają nie te strony, które mówią najgłośniej, tylko te, które konsekwentnie rozwiązują konkretny problem i pokazują, że autor naprawdę wie, o czym pisze.
Jeżeli wiemy już, co wzmacnia wiarygodność, trzeba równie uczciwie nazwać to, co najczęściej ją psuje - bo tam zwykle leżą najszybsze wygrane.
Co najczęściej psuje indeksację i obniża zaufanie
Najwięcej błędów, które widzę w audytach, nie ma nic wspólnego z wielką strategią SEO. To drobiazgi: niepotrzebne duplikaty, źle ustawiony canonical, content ukryty za interakcją użytkownika albo blokada, która przypadkiem odcina ważne zasoby.
| Problem | Jak wygląda w praktyce | Co zrobić |
|---|---|---|
| Zła blokada w robots.txt | Robot nie może wejść na stronę, więc nie widzi jej treści ani metadanych. | Odblokuj crawl dla stron, które mają się indeksować; blokuj tylko to, co naprawdę ma zostać poza zasięgiem. |
| Niechciane noindex | Strona jest dostępna, ale po crawlu wypada z indeksu. | Usuń tag lub nagłówek, jeśli to błąd, i pozwól robotowi ponownie odwiedzić URL. |
| Duplikaty i warianty URL | Ta sama treść występuje pod wieloma adresami, często z parametrami. | Ustal jedną wersję kanoniczną, użyj przekierowań i linkuj wewnętrznie do właściwego adresu. |
| Treść ładowana dopiero po interakcji | Google nie widzi materiału, jeśli trzeba coś kliknąć, przewinąć albo wykonać akcję. | Zapewnij, by kluczowa treść ładowała się w widoku bez akcji użytkownika. |
| Błędy serwera i soft 404 | Strony odpowiadają niestabilnie albo udają puste zasoby. | Napraw 5xx, zwracaj 404 lub 410 dla treści usuniętych na stałe i ogranicz 429/503. |
| Problemy mobile-first | Wersja mobilna ma mniej treści, inne meta tagi albo blokowane zasoby. | Utrzymaj równoważność treści i metadanych na mobile i desktopie. |
Jest jeszcze jeden konkretny szczegół, który łatwo przeoczyć: jeśli serwer przez dłużej niż 2 dni odpowiada błędami 503 albo 429, Google może zacząć usuwać takie adresy z indeksu. To już nie jest kosmetyka, tylko realna utrata widoczności.
Właśnie dlatego zaufanie do strony buduje się nie tylko contentem, ale też higieną techniczną. A skoro znamy typowe źródła problemów, warto rozpisać prosty plan naprawczy, który da się wdrożyć bez chaosu.
Jak to poprawić krok po kroku na stronie
Gdybym miał uporządkować pracę nad serwisem od zera, zacząłbym od rzeczy banalnych, ale skutecznych. Najpierw sprawdzam, czy robot może wejść na stronę, potem czy widzi właściwą wersję, a dopiero później oceniam samą treść.
- Zweryfikuj dostępność - sprawdź, czy najważniejsze URL-e odpowiadają statusem 200, nie są blokowane i nie generują błędów renderowania.
- Przejrzyj robots.txt, noindex i canonicale - te trzy elementy najczęściej odpowiadają za niechciane wypadanie stron z indeksu albo za mieszanie sygnałów.
- Ustal jedną wersję kanoniczną każdej ważnej podstrony - canonical to wskazówka, nie rozkaz, ale bez porządku Google częściej wybiera wersję, której nie chcesz promować.
- Odchudź duplikaty - parametry filtrów, sortowanie, paginacja i kopie testowe potrafią zjadać crawl budget. Crawl budget to po prostu zestaw URL-i, które Google może i chce na danej witrynie odwiedzać.
- Popraw linkowanie wewnętrzne - najważniejsze treści powinny być łatwe do znalezienia z poziomu menu, kategorii i artykułów powiązanych.
- Uaktualnij sitemapę - zostaw w niej tylko sensowne, kanoniczne adresy i nie wrzucaj śmieciowych wariantów URL.
- Sprawdź mobile i JS - jeśli treść ładuje się dopiero po przewinięciu, kliknięciu albo skrypcie, robot może zobaczyć wersję uboższą niż użytkownik.
- Poproś o ponowny crawl tylko tam, gdzie to ma sens - Google może pobrać ponowne zgłoszenie, ale nie gwarantuje natychmiastowej indeksacji, więc warto priorytetyzować najważniejsze adresy.
Na dużych serwisach, zwłaszcza tam, gdzie szybko zmieniają się tysiące URL-i, wchodzi jeszcze temat crawl budgetu. Google Search Central podaje, że przy bardzo dużych lub bardzo dynamicznych witrynach warto kontrolować nie tylko indeksację, ale też stary i nowe wersje adresów, duplikaty oraz wydajność serwera. To nie jest detal dla perfekcjonistów, tylko codzienność e-commerce, marketplace’ów i portali z wieloma filtrami.
Kiedy ten plan jest wdrożony, zostaje jeszcze jedna rzecz: mierzenie efektów bez zgadywania. I tu naprawdę widać różnicę między stroną „zdaje się działać” a stroną, która faktycznie rośnie.
Jak mierzyć efekt bez zgadywania
Ja nie ufam wrażeniom typu „wydaje mi się, że Google lepiej nas widzi”. Do oceny indeksacji i zaufania potrzebne są konkretne sygnały, najlepiej z kilku źródeł naraz. Najprościej zacząć od Search Console, bo to ona pokazuje, co robot faktycznie robi z URL-ami.
- URL Inspection - sprawdza, jak Googlebot widzi konkretny adres, jaki wybrał canonical i czy treść została wyrenderowana poprawnie.
- Page Indexing report - pokazuje powody wykluczenia, np. noindex, duplikaty, przekierowania czy błędy skanowania.
- Crawl Stats - pomaga zauważyć, czy Googlebot odwiedza witrynę regularnie, czy raczej zaczyna ograniczać aktywność.
- Logi serwera - dają najbardziej surowy obraz tego, co naprawdę pobiera bot, kiedy wraca i gdzie traci czas.
- Widoczność organiczna - wzrost impressions i liczby sensownie zaindeksowanych stron ma znaczenie dopiero wtedy, gdy techniczne fundamenty są uporządkowane.
W dokumentacji Google jest też ważna uwaga praktyczna: jeśli chcesz sprawdzić, czy strona została poprawnie odczytana, patrz na renderowany HTML, a nie tylko na to, co widzisz w przeglądarce jako użytkownik. To szczególnie ważne przy lazy-loadzie i infinite scrollu, bo Google Search nie „klika” za człowieka i nie przewija strony jak użytkownik.
Warto też pamiętać o kanonikalizacji. To proces wyboru reprezentatywnego adresu dla duplikatów lub bardzo podobnych stron. W praktyce oznacza to, że Google może uznać inną wersję URL-a za bardziej właściwą niż ta, którą wskazałeś, a sygnały typu przekierowanie, canonical i sitemap działają najmocniej wtedy, gdy są ze sobą spójne. Ja zawsze sprawdzam, czy te trzy warstwy mówią jednym głosem.
Kiedy już wiesz, jak mierzyć efekt, zostaje najważniejsze pytanie: co z tym zrobić długoterminowo, żeby nie wracać co kwartał do tych samych błędów?
Co zostaje z tego tematu w praktyce przy nowym planie treści
Jeśli mam zamknąć cały temat jednym zdaniem, powiedziałbym tak: najpierw ułatw robotom zrozumienie strony, potem wzmacniaj jej wiarygodność treścią i strukturą linków. W 2026 roku to nadal działa lepiej niż pogoń za mitycznym jednym wskaźnikiem zaufania.
W praktyce najlepiej wygrywają serwisy, które mają czystą architekturę informacji, jedną kanoniczną wersję każdego ważnego adresu, sensowne linkowanie wewnętrzne i content, który nie próbuje być wszystkim naraz. To właśnie taki porządek sprawia, że indeksacja przebiega szybciej, a zaufanie nie rozprasza się na duplikaty, błędy techniczne i przypadkowe strony.
Jeśli budujesz nowy dział, nowy blog albo rozbudowujesz portal technologiczny, zaczynaj od tych fundamentów. Reszta jest ważna, ale bez nich nawet dobry materiał za długo czeka na właściwe miejsce w indeksie.