
Najkrócej rzecz ujmując, AI uczy się na danych, ale wynik zawsze trzeba ocenić w kontekście
- Model AI nie „myśli” jak człowiek, tylko rozpoznaje wzorce i wylicza najbardziej prawdopodobny wynik.
- Dane są paliwem całego procesu, a ich jakość często decyduje o jakości odpowiedzi.
- Uczenie maszynowe to sposób trenowania systemu na przykładach, zamiast ręcznego programowania każdej reguły.
- Generatywna AI tworzy tekst, obrazy lub kod, przewidując kolejne elementy na podstawie kontekstu.
- Największe ryzyko pojawia się tam, gdzie błąd ma koszt finansowy, prawny albo zdrowotny.
Z czego składa się nowoczesny system AI
Gdy tłumaczę ten temat, zaczynam od jednego rozróżnienia: AI to nie jeden program, lecz układ kilku warstw, które muszą zagrać razem. Najczęściej w grę wchodzą dane, model, proces uczenia, a potem jeszcze etap użycia w realnym narzędziu. Jeśli któraś z tych warstw jest słaba, cały efekt też będzie słaby.
Model to w uproszczeniu zestaw matematycznych parametrów, które zostały wytrenowane tak, by reagować na wzorce ukryte w danych. Parametry są po prostu liczbami sterującymi zachowaniem modelu. Im lepiej dopasowane do zadania, tym sensowniejsza odpowiedź w praktyce. Sam model bez dobrych danych nie zrobi jednak cudów.
- Dane uczą system, czego ma szukać i jakie zależności uznawać za istotne.
- Algorytm mówi modelowi, jak ma korygować błędy podczas nauki.
- Infrastruktura daje moc obliczeniową potrzebną do trenowania i działania na dużą skalę.
- Walidacja sprawdza, czy model działa na nowych przykładach, a nie tylko na tych, które już widział.
W praktyce właśnie tu pojawia się pierwsza różnica między narzędziem „sprytnym” a naprawdę użytecznym: jedno potrafi dobrze wyglądać na demo, drugie utrzymuje jakość po wdrożeniu. Sam opis architektury nie wystarczy, bo kluczowe jest jeszcze to, jak model uczy się na danych i jak trafia do produkcji.
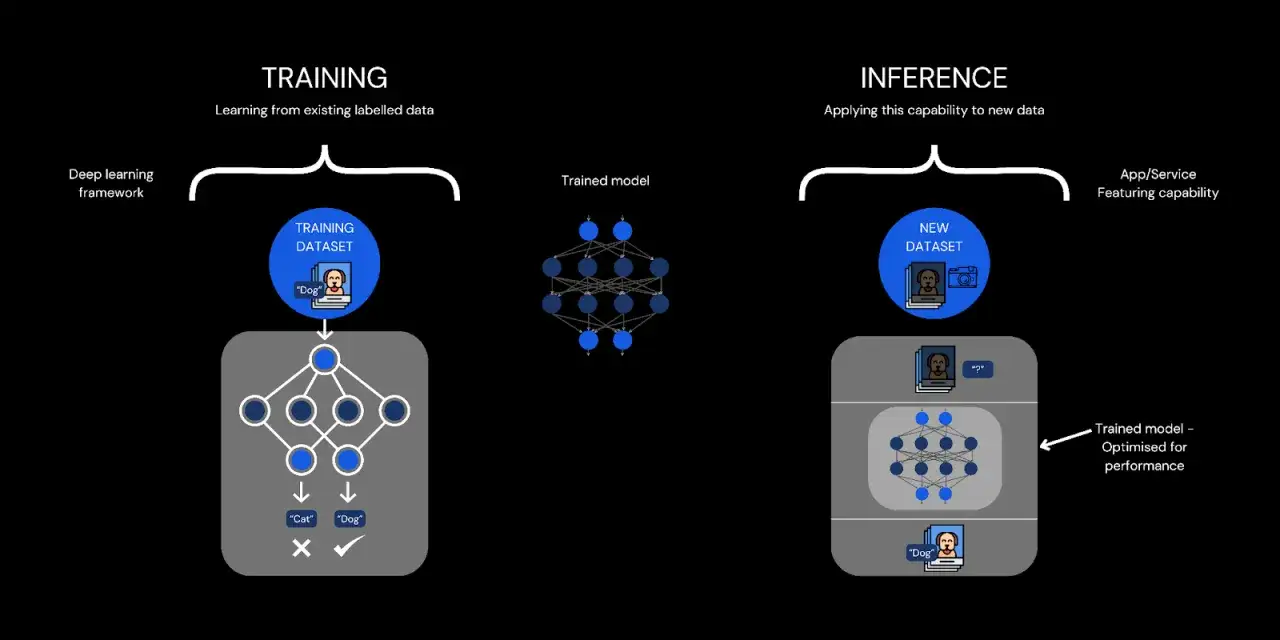
Jak model przechodzi od danych do odpowiedzi
Najprościej można to opisać jako łańcuch: dane trafiają do systemu, model uczy się na nich wzorców, potem jest testowany, a na końcu odpowiada na nowe zapytania. Ten ostatni etap nazywa się inferencją, czyli momentem, w którym wytrenowany model wykonuje zadanie w praktyce.
Zbieranie i przygotowanie danych
Na początku dane trzeba zebrać, oczyścić i uporządkować. To etap mniej efektowny niż same „inteligentne” odpowiedzi, ale właśnie tu zapada większość decyzji o jakości. Jeśli zbiór zawiera duplikaty, błędne etykiety albo zbyt mało różnorodnych przykładów, model szybko nauczy się złych skrótów myślowych. W projektach komercyjnych ten etap bywa najdroższy czasowo, bo wymaga selekcji, anonimizacji i kontroli jakości.
Trening modelu
Podczas treningu model dostaje przykłady wejścia i oczekiwane wyniki, a następnie stopniowo koryguje swoje parametry. Celem jest zmniejszanie błędu. Technicznie często robi się to metodami opartymi na optymalizacji gradientowej, czyli szukaniu takich ustawień modelu, które prowadzą do lepszych odpowiedzi. To właśnie tutaj AI „uczy się” wzorców, ale nie w sensie ludzkiego rozumienia, tylko statystycznego dopasowania.
Walidacja i testy
Po treningu model trzeba sprawdzić na danych, których wcześniej nie widział. Ten etap ma odpowiedzieć na pytanie, czy system naprawdę się nauczył, czy tylko zapamiętał przykłady. W praktyce patrzy się nie tylko na jedną miarę skuteczności, ale też na liczbę błędów w różnych klasach przypadków, odporność na szum i stabilność odpowiedzi. Dobrze działający model to nie taki, który świetnie wypada na slajdzie, lecz taki, który zachowuje jakość na nowych danych.
Wdrożenie i ciągła kontrola
Po wdrożeniu model zaczyna pracować na żywych danych. I tu pojawia się ważny problem: świat się zmienia. Jeśli zachowania użytkowników, język, ceny, przepisy albo typy dokumentów przesuną się za bardzo, model może zacząć działać gorzej mimo tego, że kiedyś był poprawny. To zjawisko nazywa się drift, czyli rozjazd między danymi treningowymi a rzeczywistością. Dlatego dobre systemy AI monitoruje się także po uruchomieniu, a nie tylko przed premierą.
Kiedy rozumiesz już ten przepływ, łatwiej odróżnić rodzaje uczenia i zobaczyć, dlaczego jedne modele nadają się do klasyfikacji, a inne do generowania treści.
Rodzaje uczenia, które stoją za większością modeli
W praktyce nie ma jednego sposobu uczenia AI. Są różne podejścia, a każde sprawdza się w innym typie zadania. To ważne, bo od metody treningu zależy zarówno jakość wyniku, jak i koszt całego projektu.
| Metoda | Na czym polega | Gdzie sprawdza się najlepiej | Najważniejsze ograniczenie |
|---|---|---|---|
| Uczenie nadzorowane | Model uczy się na danych z poprawnymi odpowiedziami, np. zdjęcie i etykieta „kot”. | Klasyfikacja, rozpoznawanie obrazów, prognozy, wykrywanie nadużyć. | Wymaga dużej liczby dobrze opisanych przykładów. |
| Uczenie nienadzorowane | System sam szuka struktur i podobieństw w danych, bez gotowych etykiet. | Segmentacja klientów, wykrywanie anomalii, grupowanie dokumentów. | Trudniej ocenić, czy znaleziony wzorzec rzeczywiście ma sens biznesowy. |
| Uczenie ze wzmocnieniem | Model dostaje nagrody lub kary za kolejne decyzje i uczy się strategii. | Robotyka, gry, sterowanie, optymalizacja sekwencji działań. | Potrafi być kosztowne i trudne do stabilnego trenowania. |
| Uczenie samonadzorowane | Model sam tworzy zadania treningowe na podstawie surowych danych. | Duże modele językowe i część nowoczesnej generatywnej AI. | Wymaga ogromnych zbiorów danych i dużej mocy obliczeniowej. |
W praktyce większość rozwiązań łączy kilka metod. Najpierw model uczy się ogólnego wzorca na ogromnym zbiorze danych, a potem jest dostrajany pod konkretny problem. To dlatego dzisiejsze systemy potrafią działać dobrze w bardzo różnych zastosowaniach, ale nie są wszechwiedzące. To właśnie ten mechanizm sprawia, że generatywne modele brzmią tak przekonująco, więc przejdźmy do ich środka.
Dlaczego generatywna AI potrafi pisać tak płynnie
Największa zmiana ostatnich lat polega na tym, że AI nie tylko klasyfikuje lub przewiduje wynik, ale też generuje treści: tekst, obraz, kod, dźwięk. W przypadku modeli językowych klucz jest prosty, choć z zewnątrz wygląda to niemal jak rozumowanie: model przewiduje następny token, czyli mały fragment tekstu, na podstawie wcześniejszego kontekstu.
Tokeny zamiast pełnych zdań
Token nie musi być całym słowem. Czasem to jego część, czasem kilka znaków, czasem całe krótkie słowo. Dzięki temu model operuje na bardzo elastycznych jednostkach języka. To ważne, bo im lepiej radzi sobie z tokenami, tym sprawniej tworzy naturalnie brzmiące zdania, ale też tym łatwiej może „dopasować się” do błędnego tropu.
Transformer i uwaga na kontekst
Współczesne modele językowe bardzo często opierają się na architekturze transformer. Jej mocną stroną jest mechanizm attention, czyli „uwagi”, który pozwala modelowi zwracać większą uwagę na te fragmenty kontekstu, które są istotniejsze dla odpowiedzi. W praktyce oznacza to, że model nie czyta tekstu liniowo jak człowiek, tylko buduje statystyczne zależności między jego częściami.
Przeczytaj również: Jak pisać prompty do ChatGPT - Poznaj skuteczne zasady i schematy
Skąd biorą się błędy i halucynacje
Najważniejsza rzecz, którą lubię podkreślać, jest bardzo prosta: model językowy nie sprawdza prawdy tak jak wyszukiwarka czy ekspert z wiedzą dziedzinową. On przewiduje najbardziej prawdopodobną kontynuację. Dlatego może pisać płynnie i jednocześnie się mylić. Tak rodzą się halucynacje, czyli odpowiedzi wyglądające wiarygodnie, ale zawierające błędne albo zmyślone informacje. Im bardziej niejednoznaczne pytanie, im słabszy kontekst i im bardziej niszowy temat, tym większe ryzyko pomyłki.
W praktyce jednak najważniejsze pytanie brzmi nie „czy to działa”, tylko „gdzie działa dobrze, a gdzie zawodzi”.
Gdzie AI daje najlepsze efekty, a gdzie się wykłada
AI najlepiej sprawdza się tam, gdzie problem jest powtarzalny, dane są liczne, a kryteria sukcesu da się dość jasno opisać. Najsłabsza jest tam, gdzie liczy się pojedyncza trafna decyzja bez marginesu na błąd, a kontekst bywa niejednoznaczny. To rozróżnienie oszczędza wielu rozczarowań.
| Obszar | Dlaczego AI radzi sobie dobrze | Na co uważać |
|---|---|---|
| Filtrowanie spamu i nadużyć | Wzorce są masowe, powtarzalne i dobrze mierzalne. | Przestępcy szybko zmieniają taktykę, więc model trzeba stale aktualizować. |
| Rekomendacje w e-commerce i mediach | System może uczyć się zachowań użytkowników na dużej próbie danych. | Zbyt agresywna personalizacja zawęża treści i pogarsza doświadczenie. |
| OCR i analiza obrazów | Model rozpoznaje powtarzalne układy kształtów, liter i obiektów. | Słabe zdjęcie, nieczytelny skan albo nietypowy układ szybko obniżają jakość. |
| Prognozowanie popytu | Historia sprzedaży i sezonowość dają modelowi konkretne sygnały. | Jednorazowe zdarzenia, np. promocje lub kryzysy, potrafią wywrócić prognozę. |
| Treści generatywne | AI świetnie tworzy szkice, warianty i streszczenia. | Może zmyślić szczegóły, więc wymaga redakcji i weryfikacji. |
Najbardziej sceptyczny jestem wobec sytuacji, w których ktoś chce oddać AI pełną decyzję tam, gdzie koszt błędu jest wysoki. Jeśli model ma 95% skuteczności, to przy 100 000 przypadków nadal daje to około 5 000 pomyłek. W medycynie, finansach albo prawie taka skala nie jest „detalem”, tylko realnym ryzykiem. Dlatego AI powinna wspierać człowieka, a nie automatycznie go zastępować.
- Halucynacje pojawiają się wtedy, gdy model brzmi pewnie, ale nie ma wystarczającego oparcia w danych lub kontekście.
- Bias oznacza uprzedzenie zapisane w danych treningowych, które potem wraca w odpowiedzi modelu.
- Drift pokazuje, że model może się zestarzeć szybciej, niż zakładał zespół wdrożeniowy.
- Overfitting sprawia, że system świetnie pamięta trening, ale gorzej radzi sobie z nowymi przypadkami.
Jeśli chcesz korzystać z AI bez rozczarowań, warto przełożyć to na kilka prostych zasad pracy.
Jak korzystać z AI rozsądnie na co dzień i w pracy
W codziennym użyciu największą różnicę robi nie sam model, tylko sposób, w jaki go karmisz zadaniem. Dobrze napisany prompt, czyli polecenie, potrafi poprawić wynik bardziej niż zmiana narzędzia. Ale sama instrukcja to nie wszystko, bo równie ważne są granice, kontrola i weryfikacja.
- Podawaj kontekst - model lepiej odpowiada, gdy wie, dla kogo tworzy treść, w jakim celu i w jakim formacie.
- Ograniczaj zakres - zamiast ogólnego „napisz o AI”, proś o konkretny fragment, poziom trudności albo typ odbiorcy.
- Nie wrzucaj wrażliwych danych - dane firmowe, osobowe i poufne powinny być używane ostrożnie i zgodnie z zasadami bezpieczeństwa.
- Sprawdzaj liczby i fakty - model może dobrze pisać, ale nadal mylić daty, nazwiska, procenty i zależności.
- Testuj na małej próbce - zanim wdrożysz AI do pracy zespołu, sprawdź ją na 20-50 realnych przykładach z Twojego procesu.
- Mierz efekt - licz czas, koszt, liczbę poprawek i błędów, bo bez tego łatwo przecenić „wrażenie” zamiast wyniku.
W pracy redakcyjnej, programistycznej czy analitycznej AI najlepiej traktować jako szybkiego asystenta: dobrego do szkicu, porządkowania informacji i przyspieszania pierwszej wersji. Ostatnie 20% jakości zwykle nadal wymaga człowieka, zwłaszcza tam, gdzie liczy się styl, precyzja albo odpowiedzialność za efekt. Na końcu zostaje tylko jedna rzecz: rozsądna ocena wyniku, zanim przyjmiesz go za pewnik.
Co warto zapamiętać, gdy oceniasz wynik modelu
Po takim rozeznaniu łatwiej zrozumieć, jak działa sztuczna inteligencja w praktyce: nie jako magiczny mózg, tylko dobrze wytrenowany system statystyczny, który bywa bardzo pomocny, ale nadal wymaga kontroli. Najlepsze rezultaty daje tam, gdzie dane są dobre, zadanie jest jasno opisane, a człowiek może sprawdzić wynik. Najmniej sensu ma tam, gdzie pojedynczy błąd jest kosztowny, a kontekst zmienia się szybciej niż model zdąży się dostroić.
Jeżeli mam zostawić jedną praktyczną zasadę, to tę: traktuj odpowiedź AI jak roboczą propozycję, a nie wyrok. Wtedy zyskujesz jej szybkość bez oddawania kontroli nad jakością.