Serwerowy pomiar w GTM, czyli gtm server-side, ma sens wtedy, gdy standardowy model zaczyna być zbyt ciężki, zbyt głośny dla przeglądarki albo zbyt mało kontrolowalny pod kątem danych. W tym tekście pokazuję, czym to rozwiązanie naprawdę jest, jak działa od strony architektury, kiedy daje przewagę, ile zwykle kosztuje i jakie błędy najczęściej psują wdrożenie. To nie jest moda dla samej mody, tylko narzędzie, które w dobrym projekcie potrafi poprawić wydajność, jakość pomiaru i kontrolę nad prywatnością.
Najważniejsze informacje o serwerowym GTM
- Serwerowy model przenosi część przetwarzania z przeglądarki na własny serwer pośredni.
- W praktyce pracują tu dwa kontenery: web container i server container.
- Największe korzyści to lepsza kontrola nad danymi, mniejsze obciążenie frontendu i łatwiejsze filtrowanie informacji wrażliwych.
- To rozwiązanie wymaga dodatkowej infrastruktury, testów i monitoringu, więc nie jest najlepsze dla każdego projektu.
- Przy automatycznym wdrożeniu na Cloud Run potrzebujesz konta GCP i aktywnego billing account.
- Koszty startują od darmowego progu w prostych konfiguracjach, ale przy większym ruchu często rosną do około 30-50 USD miesięcznie za serwer.
Czym jest serwerowy GTM i co zmienia w pomiarze
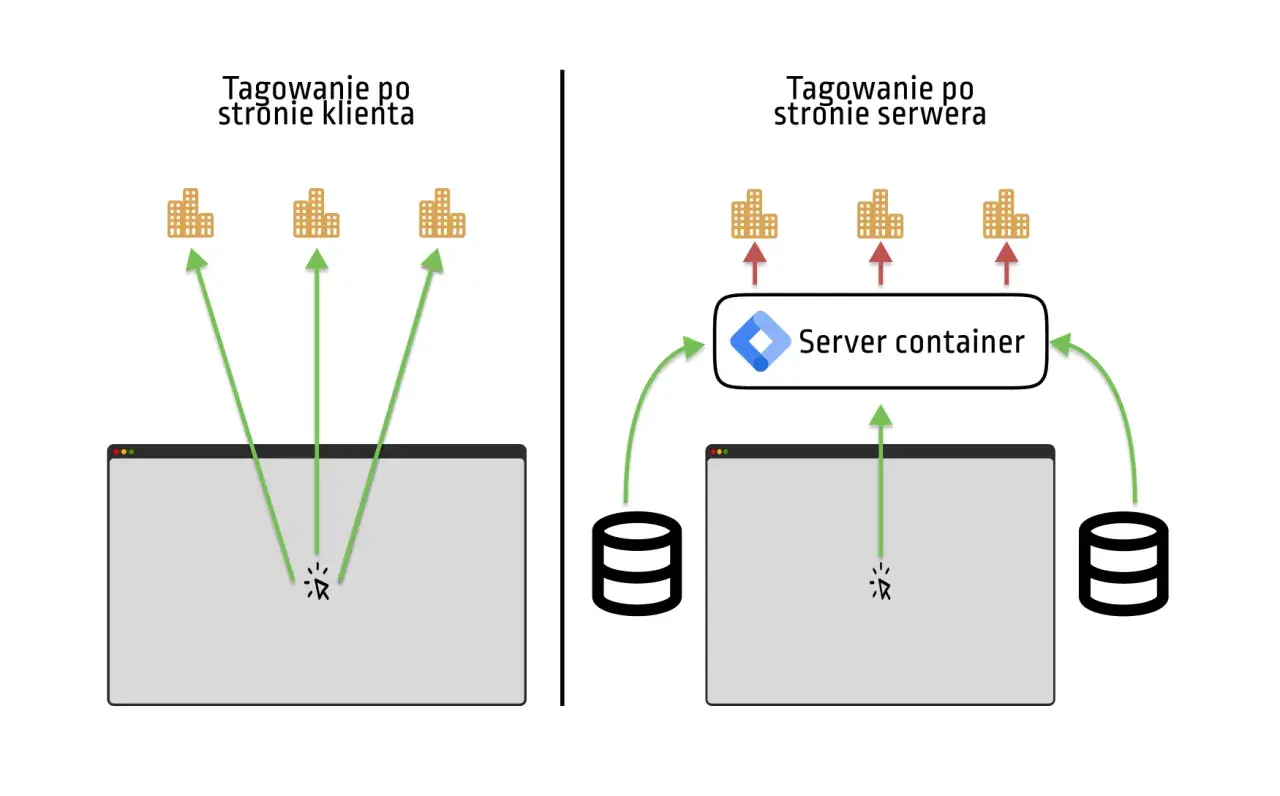
Najprościej mówiąc, chodzi o to, żeby przeglądarka nie rozmawiała bezpośrednio z wieloma narzędziami naraz. Zamiast tego wysyła jedno zdarzenie do twojego serwera, a dopiero on rozsyła je dalej do GA4, Google Ads, partnerów reklamowych albo innych endpointów. Dzięki temu zyskujesz punkt pośredni, nad którym faktycznie masz kontrolę.
To ważne rozróżnienie: serwerowy GTM nie zastępuje całego tagowania na stronie. Nadal potrzebujesz warstwy webowej, bo to ona zbiera zdarzenia z witryny, formularzy, koszyka czy kliknięć. Różnica polega na tym, że cięższa część pracy odbywa się już poza przeglądarką. Dla czytelnika technicznego to zwykle oznacza mniej chaosu w front-endzie, a dla biznesu lepszą szansę na stabilniejszy pomiar.
Ja patrzę na to tak: jeśli twoja implementacja analityki przypomina zestaw wielu bezpośrednich połączeń z różnymi usługami, serwer pośredni porządkuje cały ruch i pozwala ustawić reguły zanim dane wyjdą poza twoją domenę. W praktyce to właśnie ten moment filtracji i normalizacji robi największą różnicę.
Jak działa architektura i czym różni się od klasycznego wdrożenia
| Cecha | Klasyczny model | Model serwerowy | Co to znaczy w praktyce |
|---|---|---|---|
| Miejsce przetwarzania | Przeglądarka użytkownika | Własny serwer pośredni | Większa kontrola po twojej stronie |
| Liczba żądań | Wiele requestów do różnych vendorów | Jedno żądanie z przeglądarki, potem rozsyłka z serwera | Mniej pracy po stronie klienta |
| Prywatność | Dane trafiają bezpośrednio do dostawców | Możesz odfiltrować dane wrażliwe przed wysyłką | Łatwiej utrzymać spójne zasady przetwarzania |
| Wydajność | Większe obciążenie frontendu | Niższe obciążenie przeglądarki | Lepszy potencjał dla szybkości strony |
| Złożoność | Prostszy start | Więcej infrastruktury i testów | To rozwiązanie dla zespołu, nie tylko dla jednej osoby |
Najważniejsza różnica nie leży w samym GTM, tylko w tym, że serwer staje się filtrem i punktem normalizacji danych. W praktyce można w nim usuwać parametry zbędne, ograniczać ryzyko wysłania danych wrażliwych i dopiero potem kierować zdarzenia do kolejnych systemów. To szczególnie przydatne tam, gdzie liczy się jakość danych, a nie tylko ich szybkie wysłanie.
Warto też pamiętać o domenie. Jeśli ustawisz własną subdomenę dla serwera, pracujesz bliżej modelu first-party, a cookies mogą być bardziej odporne na zmiany po stronie przeglądarek. To nie jest detal kosmetyczny, tylko praktyczny element wpływający na trwałość pomiaru.
Kiedy to ma sens, a kiedy lepiej zostać przy prostszym układzie
W polskich projektach najczęściej widzę sens w e-commerce, portalach contentowych, serwisach leadowych i kampaniach performance, gdzie każdy poprawnie zebrany event ma realną wartość. Jeśli masz dużo tagów, kilka narzędzi marketingowych i rosnące wymagania prywatności, serwerowy tor zaczyna się bronić szybciej niż w małej, prostej stronie wizytówce.
To rozwiązanie ma sens, gdy:
- strona wysyła dużo zdarzeń i wiele z nich trafia do różnych narzędzi,
- chcesz lepiej kontrolować, jakie dane opuszczają twoją domenę,
- zależy ci na odciążeniu przeglądarki i uporządkowaniu frontendu,
- pracujesz w środowisku, gdzie consent i zgodność z polityką danych są ważne operacyjnie,
- masz zespół, który potrafi utrzymać infrastrukturę i testy.
Lepiej odpuścić albo odłożyć wdrożenie, gdy:
- masz mały ruch i kilka prostych zdarzeń, które dobrze działają w klasycznym GTM,
- nie masz zasobów na monitoring, aktualizacje i kontrolę kosztów,
- pomiar jest już dziś chaotyczny, bo problem leży w data layer, a nie w samym modelu wysyłki,
- zespół oczekuje natychmiastowego efektu bez pracy nad architekturą analityki.
Ja zwykle mówię tak: jeśli problemem jest bałagan w zdarzeniach, serwer go nie naprawi. Jeśli problemem jest sposób, w jaki dane opuszczają stronę, wtedy serwerowy model potrafi pomóc bardzo konkretnie. I właśnie od tego pytania warto zacząć, zanim przejdzie się do wdrożenia.
Jak wygląda wdrożenie krok po kroku
Najpierw warto uporządkować dane źródłowe. Jeśli warstwa danych jest niespójna, serwer tylko będzie przekazywał dalej ten sam bałagan. Dopiero potem ma sens przejście do osobnego kontenera serwerowego, który stanie się punktem przyjmowania i przetwarzania eventów.
Wariant automatyczny
To najprostsza ścieżka, jeśli chcesz szybko wystartować i nie budować całej infrastruktury ręcznie. Tworzysz kontener serwerowy, uruchamiasz automatyczne provisionowanie i dostajesz środowisko oparte o Cloud Run. Taki model wymaga konta Google Cloud i aktywnego rozliczania, ale oszczędza sporo czasu na początku.
Ten wariant lubię polecać wtedy, gdy zespół chce najpierw sprawdzić sens rozwiązania, a dopiero później decydować o bardziej rozbudowanej architekturze. To rozsądne podejście, bo pozwala przetestować przepływ danych bez inwestowania w pełny własny stack od pierwszego dnia.
Wariant manualny
Jeśli masz własną infrastrukturę albo konkretne wymagania compliance, możesz wdrożyć serwer ręcznie, także poza Google Cloud. W praktyce oznacza to użycie obrazu Docker i osobne przygotowanie środowiska preview oraz właściwego klastra tagującego. To jest ścieżka dla zespołów, które chcą mieć większą kontrolę nad infrastrukturą albo już mają ustalone standardy wdrożeniowe.
Tu jest jeden ważny niuans: preview i ruch produkcyjny to dwa różne byty, więc nie należy ich traktować jak jednego uniwersalnego serwera. Przy ręcznym wdrożeniu trzeba pilnować zmiennych konfiguracyjnych, certyfikatów HTTPS i spójnego adresowania domeny. To nie jest trudne, ale wymaga dyscypliny.
Przeczytaj również: HTML co to oznacza w praktyce - Poznaj zasady i unikaj błędów
Co sprawdzam po starcie
- Czy eventy faktycznie trafiają do kontenera serwerowego, a nie omijają go przypadkiem.
- Czy domena serwera jest ustawiona jako subdomena własnej witryny.
- Czy preview działa poprawnie i pozwala debugować przepływ danych.
- Czy po stronie web container nie zostały stare, dublujące się tagi.
- Czy consent jest inicjowany w każdym kontenerze, jeśli pracujesz na wielu konfiguracjach.
- Czy po uruchomieniu ruchu produkcyjnego monitorujesz błędy, logi i obciążenie.
Najwięcej problemów pojawia się nie przy samym klikaniu w interfejs, tylko przy przejściu z testu do produkcji. Dlatego wolę traktować wdrożenie jak proces, a nie jak jednorazową zmianę ustawienia. To oszczędza później wiele godzin debugowania.
Ile to kosztuje i co naprawdę generuje koszty
Tu najłatwiej o złudzenie, że serwerowy model jest „darmowy”, bo samo narzędzie GTM nie pobiera opłaty za kontener. W rzeczywistości płacisz za infrastrukturę. Przy prostym wdrożeniu na Cloud Run konfiguracja bywa darmowa w wielu przypadkach, ale po rozbudowie środowiska trzeba liczyć się z budżetem rzędu 30-50 USD miesięcznie za serwer, a w jednej z typowych konfiguracji Google podaje około 45 USD za miesiąc na serwer.
| Element kosztowy | Kiedy rośnie | Na co uważać |
|---|---|---|
| Hosting i obliczenia | Przy większym ruchu i większej liczbie instancji | Warto ustawić alerty kosztowe, zanim ruch zacznie skakać |
| Logi | Przy dużej liczbie requestów | Przy bardzo dużym wolumenie logowanie potrafi stać się realnym wydatkiem |
| Redundancja | Gdy chcesz utrzymać kilka instancji | Więcej instancji oznacza większą odporność, ale też wyższy rachunek |
| Multi-region | Gdy obsługujesz ruch globalny | Dobra opcja przy skali, ale tylko jeśli naprawdę jej potrzebujesz |
W praktyce nie patrzę na koszty tylko przez pryzmat miesięcznej faktury. Patrzę też na czas zespołu, utrzymanie, testy i ryzyko błędów. Jeżeli masz niski ruch, prosty sklep lub niewielki portal, klasyczny model nadal może być rozsądniejszy. Jeżeli jednak zależy ci na kontroli i jakości danych, koszt bywa łatwiejszy do obrony niż kolejne komplikacje w przeglądarce.
Jest jeszcze jeden istotny detal: przy większym ruchu logi mogą zacząć kosztować więcej, niż się spodziewasz. Dlatego rozsądnie jest od razu ustawić monitoring wydatków, a nie odkrywać po miesiącu, że debugowanie stało się osobnym punktem budżetu.
Najczęstsze błędy, które psują wdrożenie
Największy błąd, jaki widzę, to oczekiwanie, że sama zmiana modelu rozwiąże problemy z analityką. Nie rozwiąże, jeśli eventy są źle nazwane, duplikowane albo wysyłane z kilku miejsc jednocześnie. Serwer tylko przyjmuje to, co dostanie.
- Przeniesienie starego chaosu z frontendu na serwer bez porządkowania data layer.
- Brak własnej subdomeny, przez co tracisz część korzyści związanych z first-party context.
- Używanie różnych identyfikatorów kontenerów na źródle i celu, co potrafi rozbić pomiar cross-domain.
- Zapominanie o consent w każdym kontenerze, zwłaszcza gdy konfiguracji jest więcej niż jedna.
- Utrzymywanie tylko jednej instancji przy rosnącym ruchu i liczenie, że „jakoś to będzie”.
- Brak kontroli logów i alertów kosztowych, przez co rachunek rośnie szybciej niż przewidywał zespół.
Jeśli miałbym wskazać jedną zasadę ochronną, powiedziałbym: najpierw mierzalność, potem infrastruktura. Najpierw porządek w zdarzeniach, potem serwer. Taka kolejność jest wolniejsza na starcie, ale po prostu działa lepiej.
Co sprawdzić, zanim przełączysz ruch
Przed wdrożeniem produkcyjnym dobrze jest odpowiedzieć sobie na kilka praktycznych pytań: jakie zdarzenia naprawdę chcesz przenieść na serwer, które narzędzia muszą zostać obsłużone, czy zespół ma czas na monitoring i kto będzie pilnował budżetu. To brzmi prozaicznie, ale właśnie takie pytania decydują o tym, czy wdrożenie będzie stabilne.
- Czy masz czystą warstwę danych i jednoznaczne nazwy eventów?
- Czy wiesz, które tagi przenosisz, a które zostają po stronie klienta?
- Czy subdomena serwera jest już przygotowana i działa po HTTPS?
- Czy masz ustawione alerty kosztowe i monitoring błędów?
- Czy sprawdziłeś zgodność przepływu danych z polityką prywatności i consent?
Jeśli te punkty są domknięte, serwerowy model ma dużą szansę dać realny efekt: lepszą kontrolę, czystsze dane i mniejsze obciążenie frontendu. Jeśli nie są, lepiej najpierw uporządkować fundamenty, bo wtedy migracja będzie nie tylko efektowna technicznie, ale też naprawdę użyteczna.