Google BigQuery to potężne narzędzie, które rewolucjonizuje sposób, w jaki firmy analizują i przetwarzają ogromne zbiory danych. Ten artykuł to kompleksowy przewodnik, który pomoże Ci zrozumieć jego bezserwerową architekturę, model cenowy, praktyczne zastosowania oraz miejsce na tle konkurencji, dostarczając wiedzy niezbędnej do podjęcia świadomych decyzji biznesowych i analitycznych.
Google BigQuery – bezserwerowa hurtownia danych do błyskawicznej analizy petabajtów
- BigQuery to w pełni zarządzana, bezserwerowa hurtownia danych w chmurze Google Cloud, eliminująca potrzebę zarządzania infrastrukturą.
- Dzięki architekturze oddzielającej obliczenia od przechowywania danych, BigQuery oferuje niezależne skalowanie i optymalizację kosztów.
- Silnik Dremel umożliwia przetwarzanie terabajtów danych w sekundy, a petabajtów w minuty, dzięki równoległemu wykonywaniu zapytań SQL.
- Model cenowy opiera się na kosztach przechowywania i przetwarzania, z opcjami on-demand (na żądanie) i capacity (ryczałt), oraz darmowymi limitami.
- Narzędzie natywnie integruje się z ekosystemem Google (GA4, Looker Studio) oraz umożliwia tworzenie modeli ML za pomocą BigQuery ML.

Czym jest Google BigQuery i dlaczego rewolucjonizuje świat analizy danych?
BigQuery to w pełni zarządzana, bezserwerowa hurtownia danych w chmurze Google Cloud Platform, stworzona z myślą o błyskawicznej analizie ogromnych zbiorów danych, sięgających nawet petabajtów, przy użyciu standardowego języka SQL. Jest to usługa typu SaaS (Software as a Service), co oznacza, że użytkownicy nie muszą martwić się o zarządzanie infrastrukturą sprzętową, serwerami czy procesami aktualizacji wszystko to leży po stronie Google.BigQuery w 30 sekund: Co to za narzędzie i jaki problem rozwiązuje?
W swojej istocie, Google BigQuery to bezserwerowa hurtownia danych w chmurze, która rozwiązuje fundamentalny problem organizacji: jak szybko i efektywnie analizować gigantyczne ilości danych bez konieczności ponoszenia ogromnych kosztów i nakładów pracy związanych z budową i utrzymaniem własnej infrastruktury. Pozwala na pracę z petabajtami danych, wykorzystując do tego powszechnie znany język SQL, co czyni go dostępnym dla szerokiego grona specjalistów.
Koniec z zarządzaniem serwerami: Na czym polega magia architektury bezserwerowej (serverless)?
Architektura bezserwerowa (serverless) w BigQuery oznacza, że jako użytkownik jesteś zwolniony z wszelkich obowiązków związanych z zarządzaniem infrastrukturą. Nie musisz martwić się o konfigurację serwerów, ich skalowanie w zależności od obciążenia, czy przeprowadzanie aktualizacji systemowych. BigQuery automatycznie alokuje i zarządza zasobami obliczeniowymi i dyskowymi w miarę potrzeb. Ta automatyzacja znacząco upraszcza operacje i pozwala zespołom skupić się na analizie danych, a nie na utrzymaniu infrastruktury.
Od terabajtów do petabajtów w kilka sekund: Jak BigQuery osiąga niespotykaną szybkość?
Imponująca szybkość BigQuery wynika z zastosowania rozproszonego silnika zapytań o nazwie Dremel. Dremel został zaprojektowany przez Google do równoległego przetwarzania ogromnych zbiorów danych. Zapytania są dzielone na mniejsze części i wykonywane jednocześnie na wielu węzłach obliczeniowych. Wyniki są następnie agregowane w czasie rzeczywistym, co pozwala na analizę terabajtów danych w ciągu sekund, a nawet petabajtów w ciągu kilku minut. To właśnie ta zdolność do masowego przetwarzania równoległego jest kluczem do wydajności BigQuery.
Dla kogo jest BigQuery? Analityk, marketer, a może inżynier danych?
BigQuery jest narzędziem niezwykle wszechstronnym, znajdującym zastosowanie w wielu rolach i branżach. Analitycy danych mogą wykorzystać je do eksploracji dużych zbiorów danych i tworzenia zaawansowanych raportów. Deweloperzy znajdują w nim potężne narzędzie do budowania aplikacji opartych na danych. Menedżerowie IT doceniają jego skalowalność i łatwość zarządzania. Osoby decyzyjne w biznesie mogą polegać na szybkich i precyzyjnych analizach do podejmowania strategicznych decyzji. Nawet marketerzy mogą czerpać korzyści z analizy danych kampanii i zachowań klientów na dużą skalę.
Kluczowe mechanizmy pod maską: Jak działa BigQuery?
Aby w pełni docenić możliwości i potencjał Google BigQuery, warto przyjrzeć się bliżej jego unikalnej architekturze i kluczowym komponentom. To właśnie one odpowiadają za jego niezwykłą wydajność, elastyczność i niezawodność, które odróżniają go od tradycyjnych rozwiązań bazodanowych.
Rozdzielenie mocy i danych: Sekret elastyczności, czyli architektura Compute vs. Storage
Jednym z fundamentalnych założeń architektury BigQuery jest ścisłe rozdzielenie warstwy przechowywania danych (storage) od warstwy obliczeniowej (compute). Oznacza to, że dane są przechowywane w systemie plików Colossus, niezależnie od zasobów obliczeniowych, które je przetwarzają. Ta separacja pozwala na niezależne skalowanie obu komponentów możemy zwiększyć moc obliczeniową bez wpływu na koszty przechowywania i odwrotnie. Dzięki temu użytkownicy płacą tylko za faktycznie wykorzystane zasoby, co przekłada się na znaczną elastyczność i optymalizację kosztów.
Silnik Dremel: Technologia Google, która napędza błyskawiczne zapytania SQL
Jak już wspomniano, sercem BigQuery jest silnik zapytań Dremel. Jest to kluczowa, opatentowana technologia Google, która umożliwia przetwarzanie ogromnych ilości danych z niespotykaną dotąd szybkością. Dremel działa na zasadzie masowego przetwarzania równoległego (MPP Massively Parallel Processing). Zapytania są rozdzielane na wiele mniejszych zadań, które są następnie wykonywane jednocześnie na setkach, a nawet tysiącach maszyn. Wyniki są błyskawicznie agregowane, co pozwala na uzyskanie odpowiedzi na złożone zapytania w czasie zbliżonym do rzeczywistego.
Globalny system plików Colossus: Jak Google przechowuje Twoje dane bezpiecznie i wydajnie?
Zaawansowana warstwa przechowywania danych w BigQuery to globalny system plików Colossus. Jest to system rozproszony, zaprojektowany z myślą o wysokiej dostępności, trwałości i bezpieczeństwie. Colossus automatycznie zarządza replikacją danych na wielu serwerach i w różnych lokalizacjach, co zapewnia ich odporność na awarie sprzętu. Dane są również fragmentowane, co ułatwia równoległy dostęp i przetwarzanie przez silnik Dremel. Dzięki Colossus Twoje dane są bezpieczne i zawsze dostępne, gdy ich potrzebujesz.
BigQuery ML: Jak tworzyć modele uczenia maszynowego za pomocą prostych zapytań SQL?
BigQuery ML (BQML) to fascynująca funkcja, która pozwala na tworzenie i wdrażanie modeli uczenia maszynowego bezpośrednio w środowisku BigQuery, przy użyciu standardowego języka SQL. Oznacza to, że nie musisz już eksportować danych do zewnętrznych narzędzi ani posiadać zaawansowanej wiedzy z zakresu data science, aby budować modele predykcyjne, klasyfikacyjne czy do segmentacji. BQML upraszcza proces machine learning, czyniąc go dostępnym dla szerszego grona użytkowników, którzy znają SQL.
Ile kosztuje potęga BigQuery? Przewodnik po modelu cenowym
Zrozumienie modelu cenowego Google BigQuery jest kluczowe dla efektywnego zarządzania kosztami i planowania budżetu. Na szczęście, jest on stosunkowo przejrzysty i opiera się na dwóch głównych filarach, które pozwalają na elastyczne dopasowanie do potrzeb firmy.
Dwa filary kosztów: Opłaty za przechowywanie (storage) a opłaty za przetwarzanie (compute)
Podstawą cennika BigQuery są opłaty za przechowywanie danych (storage) oraz opłaty za przetwarzanie zapytań (compute). Koszt przechowywania jest naliczany za ilość danych, które przechowujesz w BigQuery. Na szczęście, pierwsze 10 GB danych miesięcznie jest zazwyczaj darmowe, co jest świetnym punktem wyjścia. Opłaty za przetwarzanie dotyczą ilości danych, które są skanowane podczas wykonywania Twoich zapytań SQL. To właśnie ten element może generować największe koszty, dlatego warto zrozumieć dostępne modele rozliczeń.
Model On-Demand (na żądanie): Kiedy płacenie za zapytanie ma największy sens?
Model cenowy "On-Demand" jest idealny dla użytkowników, którzy dopiero zaczynają swoją przygodę z BigQuery, mają nieregularne obciążenia analityczne lub pracują w mniejszych zespołach. W tym modelu płacisz za faktyczną ilość danych przetworzonych przez każde zapytanie. Co ważne, pierwsze 1 TB danych przetwarzanych miesięcznie jest darmowe, co stanowi znaczącą ulgę na start. Ten model oferuje dużą elastyczność, ale jego koszty mogą być mniej przewidywalne, jeśli obciążenie analityczne jest bardzo wysokie i stałe.
Model Capacity (ryczałt): Jak uzyskać przewidywalne koszty przy stałym obciążeniu?
Jeśli Twoja organizacja generuje duże i stałe obciążenie analityczne, model "Capacity" (znany również jako ryczałt lub płaskie stawki) może być bardziej opłacalny. W tym modelu rezerwujesz określoną moc obliczeniową (tzw. sloty) na określony czas (np. miesięcznie lub rocznie). Płacisz stałą, z góry określoną kwotę, niezależnie od tego, ile danych faktycznie przetworzysz. Gwarantuje to przewidywalność kosztów, co jest kluczowe dla planowania budżetu w większych firmach. Wymaga jednak lepszego prognozowania potrzeb obliczeniowych.
Ukryte koszty i darmowe limity: Na co zwrócić uwagę, aby nie przepłacać?
Chociaż BigQuery oferuje hojne darmowe limity (10 GB przechowywania i 1 TB przetwarzania miesięcznie), warto pamiętać o potencjalnych dodatkowych kosztach. Mogą one obejmować opłaty za przesyłanie danych między różnymi regionami Google Cloud (cross-region data transfer) lub za wykorzystanie funkcji strumieniowania danych w czasie rzeczywistym. Aby uniknąć przepłacania, kluczowe jest stosowanie dobrych praktyk, takich jak partycjonowanie i klastrowanie tabel, optymalizacja zapytań SQL oraz regularne monitorowanie zużycia zasobów w konsoli Google Cloud.

Praktyczne zastosowania BigQuery: Od raportów po sztuczną inteligencję
Google BigQuery to znacznie więcej niż tylko zaawansowana hurtownia danych. To wszechstronne narzędzie, które otwiera drzwi do szerokiego wachlarza praktycznych zastosowań, wspierając analizę danych w niemal każdym obszarze działalności firmy.
Integracja z Google Analytics 4: Jak uzyskać dostęp do surowych danych i pełnego obrazu użytkownika?
Jednym z najpopularniejszych zastosowań BigQuery jest integracja z Google Analytics 4 (GA4). Pozwala ona na eksport surowych danych z GA4 do BigQuery, co daje pełną kontrolę nad informacjami o zachowaniach użytkowników na stronie internetowej czy w aplikacji. Dzięki temu można tworzyć niestandardowe raporty i analizy, które wykraczają poza możliwości standardowego interfejsu GA4, budując znacznie pełniejszy i bardziej szczegółowy obraz ścieżki klienta.
Zasilanie dashboardów w czasie rzeczywistym: Tworzenie dynamicznych raportów w Looker Studio (i nie tylko)
BigQuery stanowi doskonałe źródło danych dla narzędzi Business Intelligence (BI), takich jak Looker Studio (dawniej Google Data Studio). Umożliwia tworzenie dynamicznych dashboardów i raportów, które są aktualizowane w czasie rzeczywistym. Wizualizacja złożonych danych w przystępny sposób wspiera szybkie podejmowanie decyzji biznesowych. Oczywiście, BigQuery integruje się również z wieloma innymi popularnymi narzędziami BI dostępnymi na rynku.
Zaawansowana analityka marketingowa: Łączenie danych z Google Ads, CRM i innych źródeł
W obszarze marketingu, BigQuery jest nieocenione do przeprowadzania zaawansowanych analiz. Pozwala na połączenie danych z różnych źródeł takich jak Google Ads, systemy CRM, dane transakcyjne, czy informacje z mediów społecznościowych. Umożliwia to uzyskanie holistycznego widoku na ścieżkę klienta, precyzyjne mierzenie zwrotu z inwestycji (ROI) kampanii marketingowych oraz optymalizację strategii w czasie rzeczywistym.
Segmentacja klientów i analiza predykcyjna z wykorzystaniem BigQuery ML
Dzięki możliwościom BigQuery ML, narzędzie to staje się potężnym silnikiem do segmentacji klientów i przeprowadzania analiz predykcyjnych. Można budować modele, które przewidują, którzy klienci są najbardziej narażeni na odejście (churn), rekomendują produkty, personalizują oferty czy identyfikują najbardziej wartościowe segmenty klientów. Wszystko to można osiągnąć, pisząc zapytania SQL, co znacząco demokratyzuje dostęp do zaawansowanych technik analitycznych.
BigQuery na tle konkurencji: Porównanie z Snowflake i Amazon Redshift
Na rynku hurtowni danych w chmurze istnieje kilka wiodących rozwiązań, a wybór między nimi często sprowadza się do porównania Google BigQuery z takimi gigantami jak Snowflake i Amazon Redshift. Każde z tych narzędzi ma swoje unikalne cechy, które mogą przechylić szalę na jego korzyść w zależności od specyficznych potrzeb organizacji.
Architektura i model działania: Serverless w BigQuery vs. wirtualne hurtownie w Snowflake
BigQuery wyróżnia się swoją w pełni bezserwerową architekturą, gdzie Google zarządza całą infrastrukturą. Snowflake również stosuje architekturę oddzielającą moc obliczeniową od przechowywania danych, ale opiera się na koncepcji "wirtualnych hurtowni", które użytkownik musi skonfigurować i zarządzać. Amazon Redshift natomiast wymaga od użytkownika zarządzania klastrami serwerów, co daje większą kontrolę, ale wiąże się z większym nakładem pracy administracyjnej. Różnice te wpływają na elastyczność, łatwość zarządzania i skalowalność każdego z rozwiązań.
Różnice w modelu cenowym: Gdzie zapłacisz więcej za elastyczność, a gdzie za prostotę?
Model cenowy BigQuery (on-demand/capacity) oferuje dużą elastyczność, szczególnie z darmowymi limitami na start. Snowflake rozlicza się za pomocą "kredytów", które kupuje się z góry, co zapewnia pewną przewidywalność, ale może być droższe przy nieregularnych obciążeniach. Amazon Redshift opiera się na kosztach instancji serwerowych, z opcjami rezerwacji, co może być opłacalne dla stałych, przewidywalnych obciążeń. Wybór zależy od tego, czy priorytetem jest elastyczność, prostota, czy przewidywalność kosztów.
Ekosystem i integracje: Dlaczego BigQuery jest naturalnym wyborem w świecie Google?
Jednym z największych atutów BigQuery jest jego natywna integracja z szerokim ekosystemem Google Cloud Platform oraz innymi usługami Google, takimi jak Google Analytics 4, Google Ads czy Looker Studio. Dla firm, które już intensywnie korzystają z narzędzi Google, BigQuery jest często najbardziej naturalnym i najłatwiejszym wyborem, oferującym płynną współpracę między usługami. Snowflake i Redshift również posiadają bogate możliwości integracji, ale zazwyczaj z własnymi ekosystemami (AWS dla Redshift) lub z narzędziami firm trzecich.
Wydajność w praktyce: Które rozwiązanie lepiej sprawdzi się przy Twoim typie zapytań?
Wydajność każdego z tych narzędzi jest silnie zależna od konkretnego przypadku użycia. BigQuery często błyszczy w przypadku zapytań ad-hoc na ogromnych zbiorach danych i eksploracji. Redshift może być bardziej optymalny dla stabilnych, powtarzalnych obciążeń analitycznych. Snowflake oferuje dużą elastyczność w obsłudze różnorodnych obciążeń. Ostateczna wydajność zawsze zależy od struktury danych, optymalizacji zapytań i specyfiki obciążenia analitycznego.
Twoje pierwsze kroki w BigQuery: Jak zacząć analizować dane?
Rozpoczęcie pracy z Google BigQuery jest prostsze, niż mogłoby się wydawać. Poniższy przewodnik krok po kroku przeprowadzi Cię przez podstawowe etapy konfiguracji i pierwszego uruchomienia, otwierając drzwi do świata zaawansowanej analizy danych.
Krok 1: Konfiguracja projektu w Google Cloud Platform – przewodnik
- Jeśli jeszcze nie posiadasz konta, pierwszym krokiem jest założenie darmowego konta w Google Cloud Platform (GCP).
- Po zalogowaniu, przejdź do konsoli GCP i utwórz nowy projekt. Projekt jest podstawową jednostką organizacyjną dla wszystkich zasobów, które będziesz tworzyć w GCP, w tym dla BigQuery.
- Google Cloud oferuje również hojny darmowy pakiet startowy, który obejmuje środki i usługi, ułatwiając rozpoczęcie pracy bez ponoszenia początkowych kosztów.
Krok 2: Ładowanie pierwszych danych – od CSV po strumieniowanie z aplikacji
Po skonfigurowaniu projektu, czas na załadowanie danych. BigQuery oferuje wiele elastycznych metod importu:
- Możesz łatwo ładować dane z plików w popularnych formatach, takich jak CSV czy JSON, przechowywanych w Google Cloud Storage.
- Istnieje również możliwość ładowania danych bezpośrednio z lokalnych plików na Twoim komputerze.
- Dla aplikacji wymagających analizy danych w czasie rzeczywistym, BigQuery wspiera strumieniowanie danych bezpośrednio z aplikacji.
- Możesz również importować dane z innych usług Google Cloud, takich jak Google Analytics 4, co jest niezwykle wygodne dla analityków internetowych.
Krok 3: Wykonanie pierwszego zapytania SQL w interfejsie BigQuery Studio
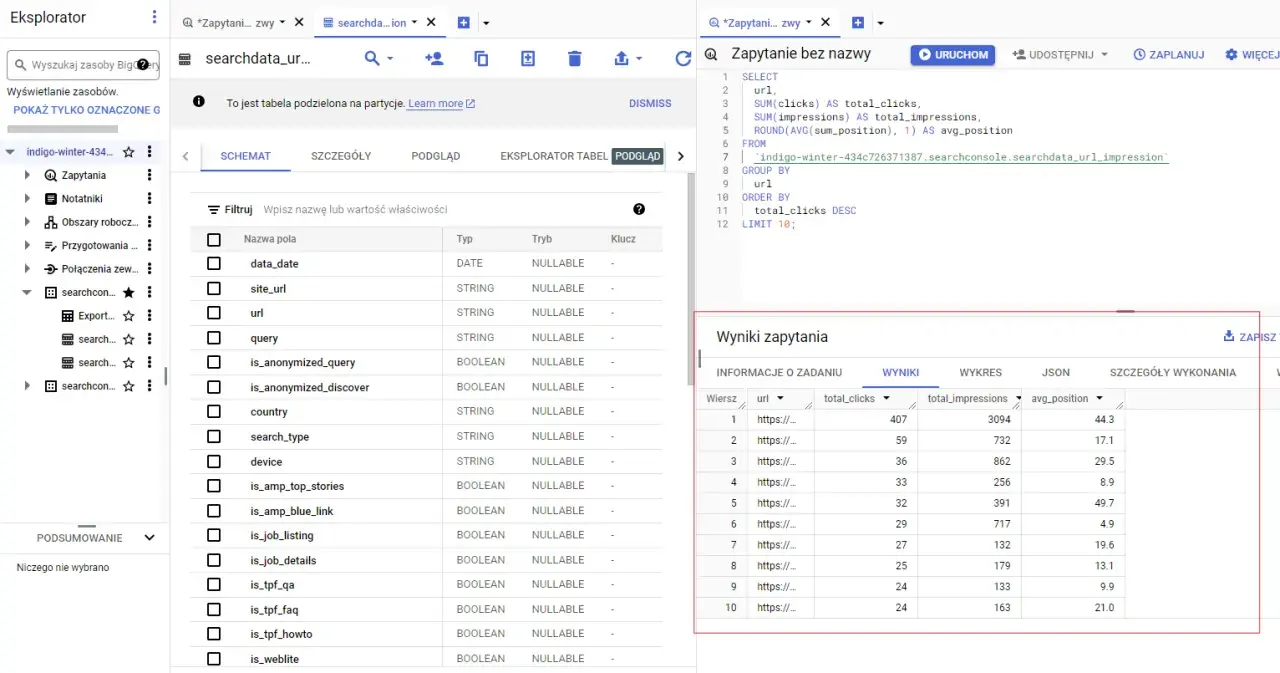
Po załadowaniu danych, nadszedł czas na ich analizę. W interfejsie BigQuery Studio w konsoli GCP, możesz napisać i wykonać swoje pierwsze zapytanie SQL. Po wybraniu projektu i zestawu danych (dataset), wystarczy wpisać proste zapytanie, na przykład `SELECT * FROM \`projekt.dataset.tabela\` LIMIT 10`, aby zobaczyć pierwsze wyniki. Pamiętaj, że podstawowa znajomość języka SQL jest kluczowa do efektywnej pracy z BigQuery.
Przeczytaj również: Cross-network w GA4 - Czy wiesz, co napędza Twoje PMax?
Najlepsze praktyki i optymalizacja zapytań: Jak pisać wydajny kod SQL w BigQuery?
Aby zapewnić maksymalną wydajność i zminimalizować koszty, warto stosować się do kilku kluczowych zasad pisania zapytań SQL w BigQuery:
- Unikaj `SELECT *`: Zawsze wybieraj tylko te kolumny, których faktycznie potrzebujesz. Skanowanie niepotrzebnych danych generuje koszty.
- Wykorzystaj partycjonowanie i klastrowanie tabel: Odpowiednie strukturyzowanie danych pozwala na szybsze filtrowanie i agregację informacji.
- Używaj podziału na partycje czasowe: Jeśli pracujesz z danymi czasowymi, partycjonowanie według daty lub godziny znacząco przyspiesza zapytania.
- Optymalizuj klauzule `WHERE` i `JOIN`: Upewnij się, że warunki filtrowania i łączenia tabel są jak najbardziej precyzyjne.
- Monitoruj koszty i wydajność: Regularnie analizuj historię zapytań, aby identyfikować potencjalne problemy i obszary do optymalizacji.